让网络蜘蛛收录网站的方法
1、首先,通过FTP连接到你的IP,找到根目录下面的robots.txt
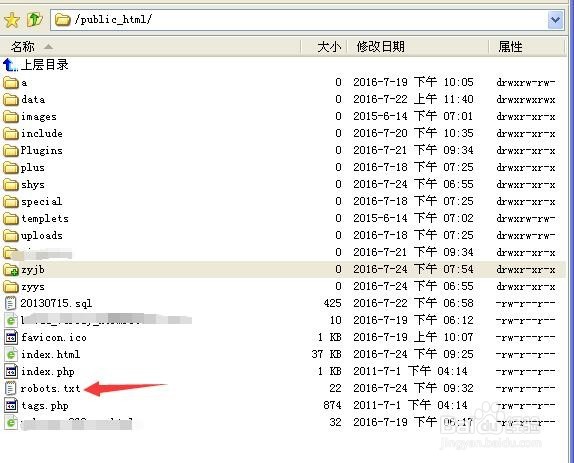
2、什么是robots文件呢?
robots是站点与spider沟通的重要渠道,站点通过robots文件声明该网站中不想被搜索引擎收录的部分或者指定搜索引擎只收录特定的部分。请注意,仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。
3、下载之后打开,查看里面的配置。
如下图,这样的配置是禁止所有搜索引擎收录你的网站
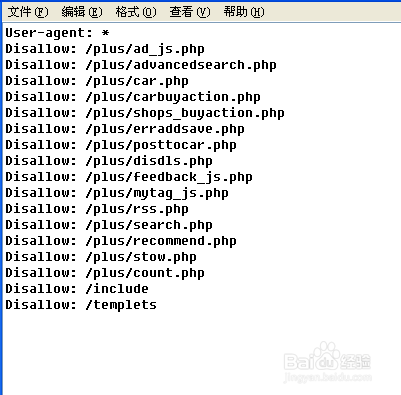
4、下图是一些robots文件的使用方法
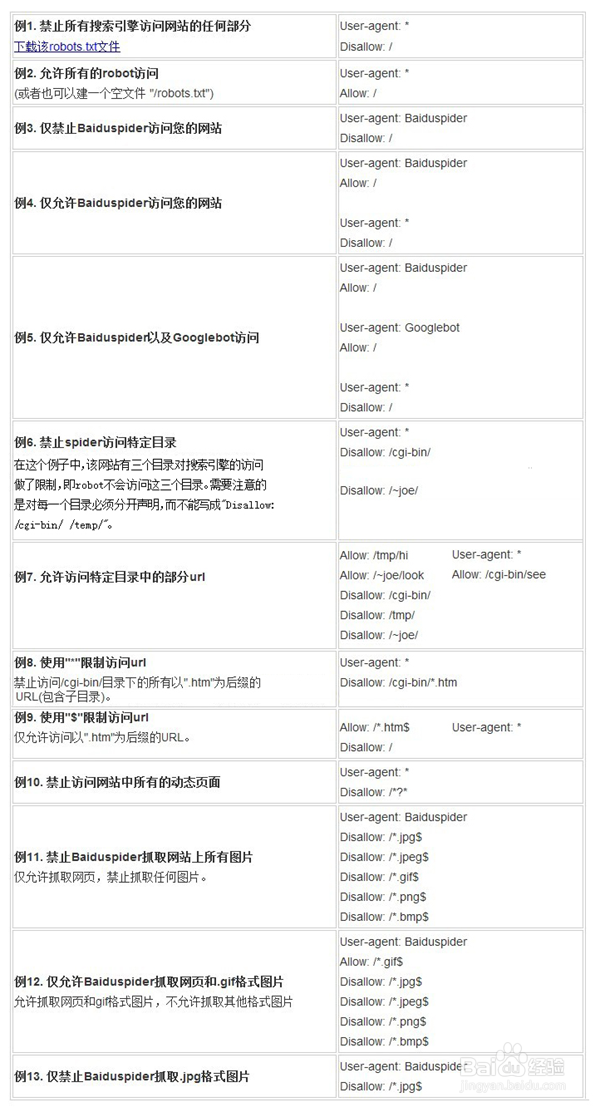
5、网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果将网站视为酒店里的一个房间,robots.txt就是主人在房间门口悬挂的“请勿打扰”或“欢迎打扫”的提示牌。这个文件告诉来访的搜索引擎哪些房间可以进入和参观,哪些房间因为存放贵重物品,或可能涉及住户及访客的隐私而不对搜索引擎开放。
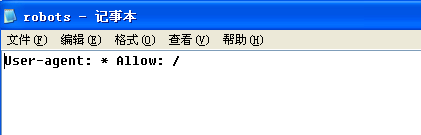
6、最后,简单地说,要是你网站存在这个文件的话,就有可能阻止了网络蜘蛛来你网站收录你的信息了。
下面这样配置就可以允许所有搜索引擎来你网站了
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:140
阅读量:169
阅读量:121
阅读量:154
阅读量:171