Beautiful Soup解析网页,Beautiful Soup的使用
1、首先什么是网页,网页组建
当我们访问网页时,我们的Web浏览器向Web服务器发出请求。然后,服务器发回文件,告诉浏览器如何为我们呈现页面。这些文件分为几种主要类型:
HTML - 包含页面的主要内容。
CSS - 添加样式以使页面看起来更好。
JS - Javascript文件为网页添加交互性。
图像 - 图像格式(如JPG和PNG)允许网页显示图片。
以上这些都是构成网页的组建,如下打开beautiful soup安装库地址,这就是一个网页

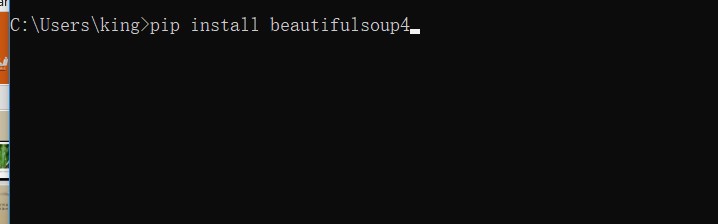
2、安装
pip installbeautifulsoup4
pip install urllib2(没有装的话要安装)
打开cmd,然后输入命令进行安装
3、使用
先读取我们要提取信息的页面使用python的 urllib2
from bs4import BeautifulSoup
import urllib2
html=urllib2.urlopen("http://127.0.0.1:8000/ceshi.html").read().decode('utf-8')
print(html)
或者
importrequests
from bs4import BeautifulSoup
page =requests.get(“http://127.0.0.1:8000/ceshi.html”) //page is response 对象
soup =BeautifulSoup(page.content, 'html.parser')
这两种方式都能取得html内容

4、我这里的话就简单爬取http://127.0.0.1:8000/ceshi.html 本地的一个页面代码如下图所示
这样就可以把 页面中的信息取出
from bs4 import BeautifulSoupfrom urllib2 import urlopenhtml = urlopen("http://127.0.0.1:8000/ceshi.html").read().decode('utf-8')soup=BeautifulSoup(html,features='lxml')print(soup.h1) #输出标题all_href = soup.find_all('img')all_href = [l['src'] for l in all_href]print( all_href) #输出该页面中的img链接

5、Beautifulsoup通过css解析网页,我们在页面中给p标签加个 样式类fontred,然后使用如下代码就可以实现p标签的内容读出来
from bs4 import BeautifulSoupfrom urllib2 import urlopenhtml = urlopen("http://127.0.0.1:8000/ceshi.html").read().decode('utf-8')soup=BeautifulSoup(html,features='lxml')print(soup.h1)soup = BeautifulSoup(html, features='lxml')month = soup.find_all('p', {"class": "fontred"})for m in month: print(m.get_text()) #输出p标签的内容

6、接着上面的 ,我们加入代码
soup1 = soup.find('ul', {"class": 'fontgreen'})soup2 = soup1.find_all('li')for d in soup2: print(d.get_text())
这样 就可以实现 将class为fontgreen的url下面的li标签文本类容输出

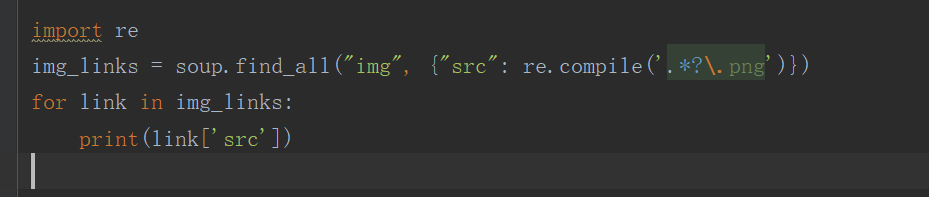
7、beautifulsoup另一个好用的功能正则表达式匹配
import reimg_links = soup.find_all("img", {"src": re.compile('.*?\.png')})for link in img_links: print(link['src'])
通过匹配 就可以把 图片地址输出