Python: Pandas 数据表拼接
1、一对一
两个表之间的公共列是一对一的。
这里的示例我们就不用图片了,直接使用代码来做展示,原因嘛就是小编懒的画了:

2、这里可以很直观的看到,这两个表的编号是公共列,并且唯一对应。
如果我们要讲这两个表进行连接操争夏返作,需要使用 merge() 方法:

3、一对多
两个表之间的公共列不是一对一的,而是其中一个表的公共列是唯一的,另一个表的公共列则会有重复的数据。

4、从上面这两个 df 中可以看到, df1 中的编号在 df3 中会对应多条数据,我们在对这两个 df 进行连接操作的时候,需要使用属性 on 指明判断的条件:

5、多对多
两个表之间的公共列都是会有重复数据的,相当于是多个一对多。
注意理解多个一对多,这里的逻辑稍微有点绕,小编在第一次接触 SQL 的时候实际上是无法理解的。
我们这里新建一个 df4 ,新增一个编号为 100 的小黑,还是通过编号对 df4 和 df3 进行连接操作:

6、连接方式
学过 SQL 的同学都知道, SQL 中连接分为内连接、左连接、右连接和外连接,同样在 Pandas 也是一样的。
内连接
内连接就是取两个表中公共的部分,我们重新创建一个 df5 ,在 df5 中只有编号 100 和 200 能和前面的数据保持一致:

7、左连接
左连接就是已左表为基础,右表像左表上拼数据:

8、右连接
右连接正好和上面的左连接相反,已右表为基础,左表往右表上拼数据:

9、外连接
外连接就是两个表的并集:

10、纵向拼接
顾名思义,纵向拼接召爱就是在纵向上对两个表进行拼接,当然这需要两个表具有相同的结构,前面我们介绍的拼接方式都在横向上进行拼接。
这里我们再加入一个 df6 ,使用 df5 和 df6 演示纵向拼接,在 Pandas 中使用纵向拼接使用的方法是 concat() :
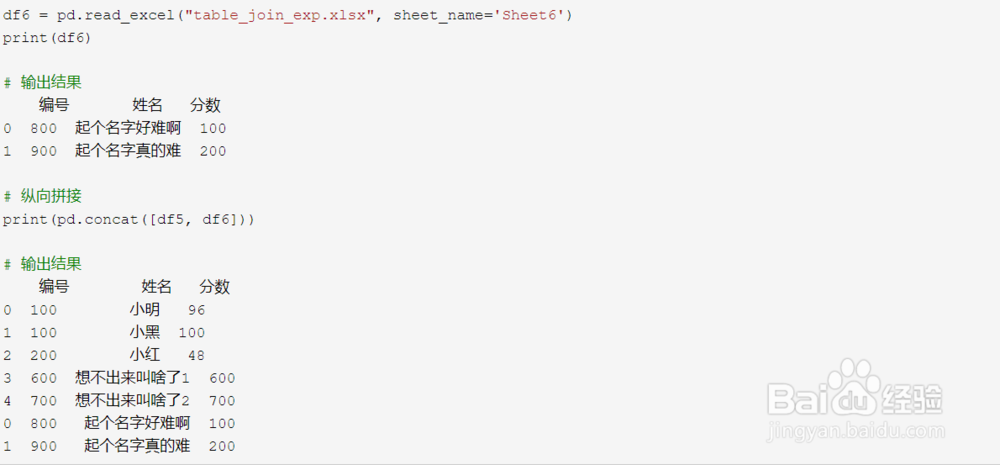
11、当我们使用 concat() 以后,发现索引还是保留了原有的索引,看着很不针叮舒服,这时我们可以设置参数 ignore_index ,让其不在保留原有索引,而是生成新的索引:
