用python下载电子书的方法
1、这里下载biquge里面的一本电子书,书名是《两界搬运工》,代码是17_17115。
之所以在这个网站下载,是因为这里的反爬措施不那么严厉,连续下载了一千二百七十七章,也没有出现封锁IP的现象。
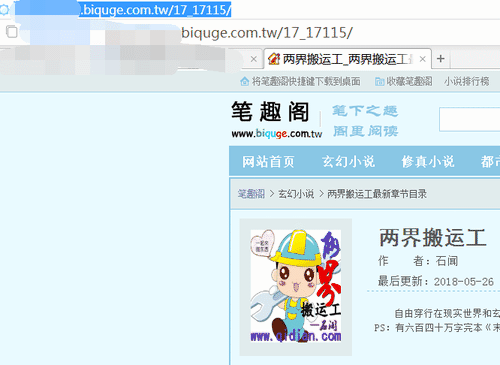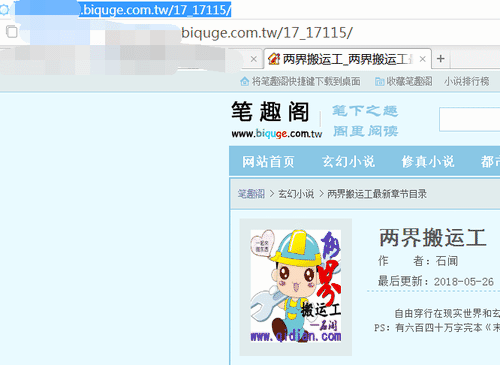
2、找到目录页,可以看到章节列表,而每一章都对应一个超链接。

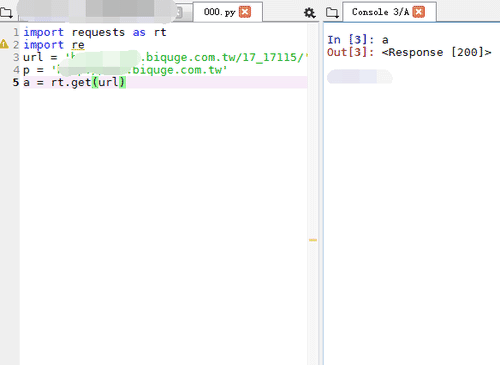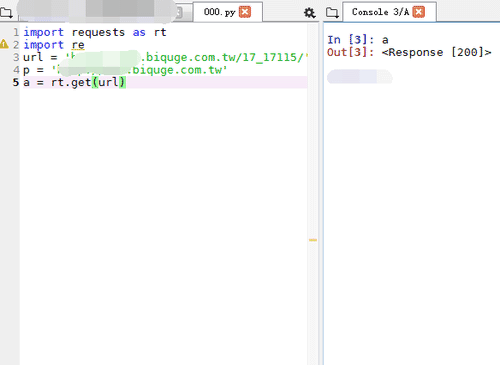
3、用python读取目录页:
import requests as rt
import re
url = '……biquge.com.tw/17_17115/'
a = rt.get(url)
print(a)
如果返回<Response [200]>,就说明这个页面读取成功了。
4、查看页面的headers,了解编码格式:
a.headers
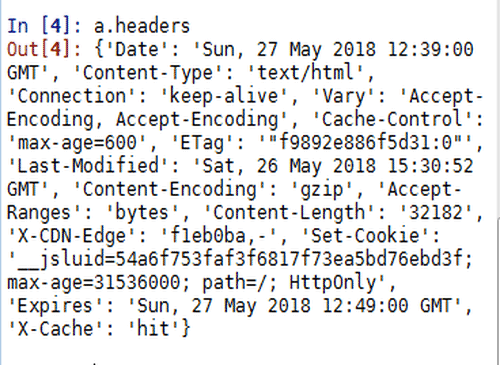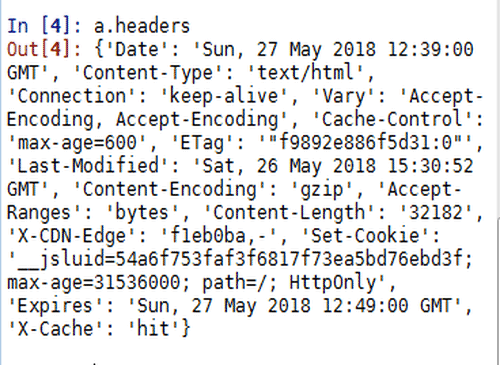
5、上面没有明确指出编码格式,尝试使用gbk编码:
a.encoding='gbk'
然后读取目录页的源代码:
b = a.text

6、用正则表达式来提取每一章的超链接:
c = re.findall('<dd><a href="(/17_17115/\d+.html)">',b)
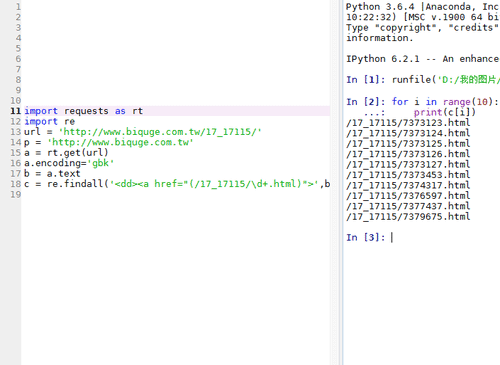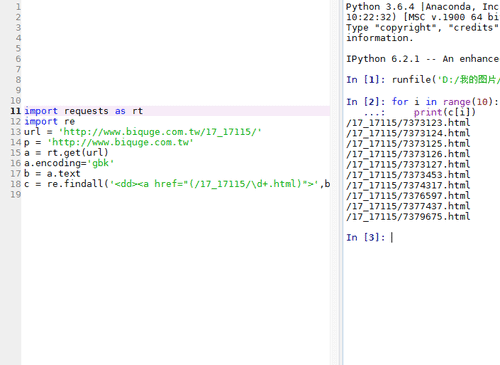
7、提取每一章的标题,需要匹配汉字字符串和空格:
d = re.findall('</a></dd><dd><a href="/17_17115/\d+.html">([\u4e00-\u9fa5 ]+)',b)

8、尝试着下载第二章的网页源代码:
p = '……biquge.com.tw'
u = rt.get(p+c[1])
u.encoding = 'gbk'
v = u.text
可以看到,网页源代码里面包含着电子书的正文内容;
每一段的开头,是四个空格( )。

9、这样,可以单独把正文的内容拿出来:
w = re.findall('( .*?)<br />',v)
但是,我们可以发现,段落开头的空格仍旧是 ,这样看着很难受是不是?因此,可以用' '替换

10、替换的方法是re.sub:
for j in w:
j = re.sub(' ',' ',j)
print(j)
这个函数的具体用法,可以参考《python里面re.sub()函数的使用方法》。

11、每一章保存为一个独立的txt文档;
把所有txt文档都放到同一个文件夹里面——
jia = u'C:\\Users\\Administrator\\Desktop\\两界搬运工\\'
整体代码如下图所示。
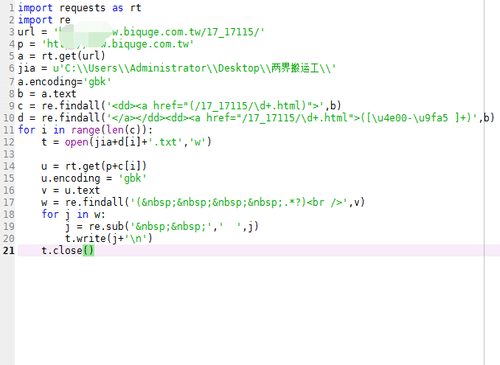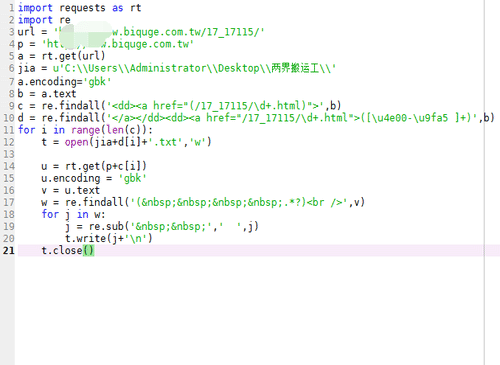
12、打开文件夹,大概半个小时,下载了1200多章。
这时候再使用百度语音合成功能,就可以让人工智能自动朗读小说了。
