Pytorch如何使用多个GPU并行
1、将已经实例化的模型在多个GPU上并行,只需要使用nn.DataParallel(model)方法即可,可用torch.cuda.device_count()检查GPU的个数

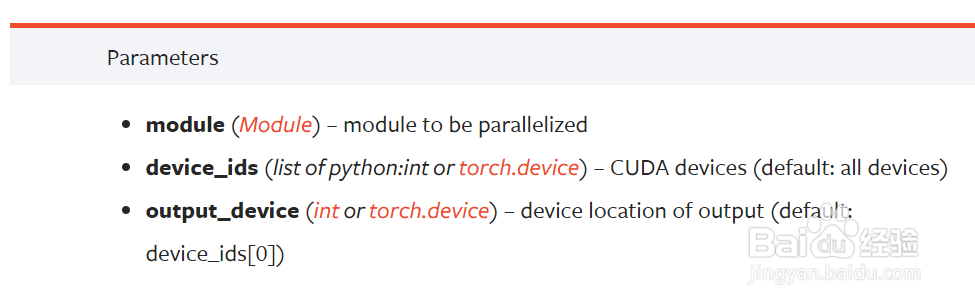
2、nn.DataParallel中的参数有三个,第一个是需要并行的模型,第二个是并败匠行所使用离番的GPU列表(默认使用所有可用GPU),第三个是模型输出所在的device编号(可以是cpu,默认是GPU0)
3、为了验证并行效果,我们定义一个打印输入和输出大小的模型,我们使叮联此用了2个GPU并行该模型

4、使用任意一个数据集,在模型输出结果后,我们再打印出输出结果的大小,与模型中的打印结果进行对比

5、In Model是模型内打印的结果,Outside为模型外打印的结果。对比发现Outside的batch大小为所有In Model之和,代表一个batch的数据被平均分到每个并行的GPU进行计算,之后再合并输出结果

声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:122
阅读量:100
阅读量:141
阅读量:172
阅读量:116