利用Python对PDF文件进行分割,合并
1、需要安装pypdf包,可以到其官网(http://pybrary.net/pyPdf/)下载,也可以可以直接下载:http://pybrary.net/pyPdf/pyPdf-1.13.win32.exe。也可以试用pip命令:pip install pypdf

2、编写代码,可以参考其官网中的例子,学习相关的API
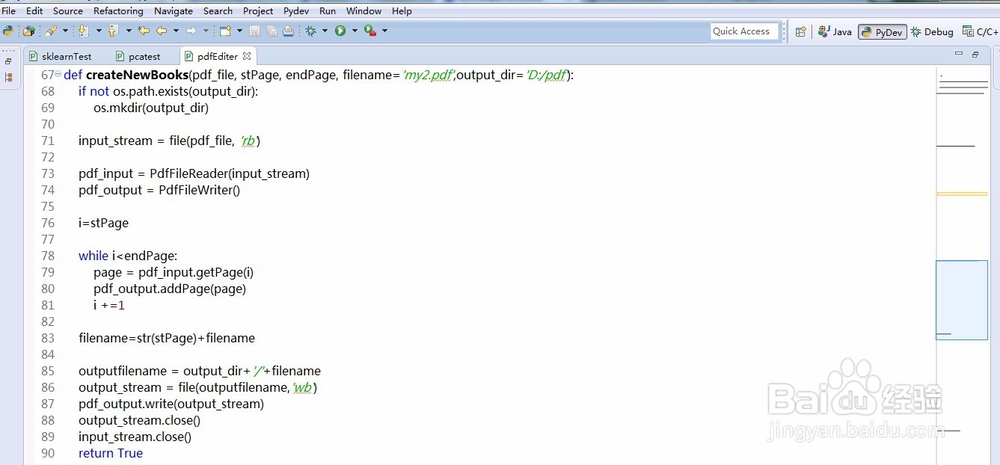
3、也可以就复制我的代码也行,已经先实现了从pdf文件中抽取指定范围的页面小重新生成一个pdf文件:
def createNewBooks(pdf_file, stPage, endPage, filename='my2.pdf',output_dir='D:/pdf'):
if not os.path.exists(output_dir):
os.mkdir(output_dir)
input_stream = file(pdf_file, 'rb')
pdf_input = PdfFileReader(input_stream)
pdf_output = PdfFileWriter()
i=stPage
while i<endPage:
page = pdf_input.getPage(i) #选取需要页面,需要注意的是第一页的编号是0
pdf_output.addPage(page) #将选好的页面加入到新的pdf中
i +=1
filename=str(stPage)+filename #给新的pdf文件命名,这个可以保证不重复覆盖
outputfilename = output_dir+'/'+filename
output_stream = file(outputfilename,'wb')
pdf_output.write(output_stream)
output_stream.close()
input_stream.close()
return True
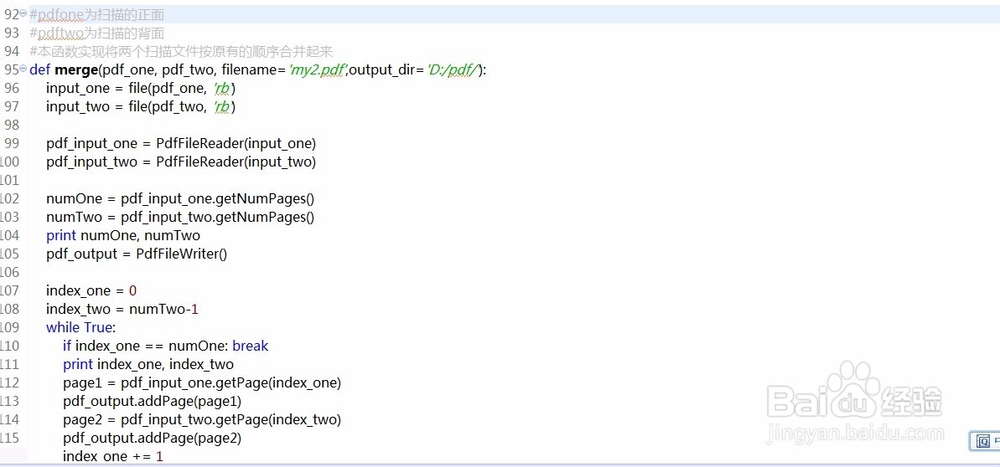
4、在日常办公中,我们经常碰到需要将页数很多,且双面都有内容的资料扫描整理,方法可以有:1)逐页扫描;这个耗时较长 2)将反面先复印,然后按顺序排列好,进行扫描,这个同样浪费纸张 3)分开正反面进行分别扫描,然后用pypdf进行按页面进行合成:
#pdfone为扫描的正面
#pdftwo为扫描的背面
#本函数实现将两个扫描文件按原有的顺序合并起来
def merge(pdf_one, pdf_two, filename='my2.pdf',output_dir='D:/pdf/'):
input_one = file(pdf_one, 'rb')
input_two = file(pdf_two, 'rb')
pdf_input_one = PdfFileReader(input_one)
pdf_input_two = PdfFileReader(input_two)
numOne = pdf_input_one.getNumPages()
numTwo = pdf_input_two.getNumPages()
print numOne, numTwo
pdf_output = PdfFileWriter()
index_one = 0
index_two = numTwo-1
while True:
if index_one == numOne: break
print index_one, index_two
page1 = pdf_input_one.getPage(index_one)
pdf_output.addPage(page1)
page2 = pdf_input_two.getPage(index_two)
pdf_output.addPage(page2)
index_one += 1
index_two -= 1
pdf_name = output_dir+filename
output_stream = file( pdf_name,'wb')
pdf_output.write(output_stream)
output_stream.close()
input_one.close()
input_two.close()
print 'Done!'