python里面re.sub()函数的使用方法
1、看下面的字符串,我们要提取出两个h标签:
text = '''
<h1 align="left" class="nnn">姓名:李隆基</h1> ,
<h3 align="right" class="mmm">打开第三方坤宁宫</h3>'''

2、用正则表达式来匹配标签:
import re
htm = re.findall(r"<h.*?>.*?</h\d>", text)
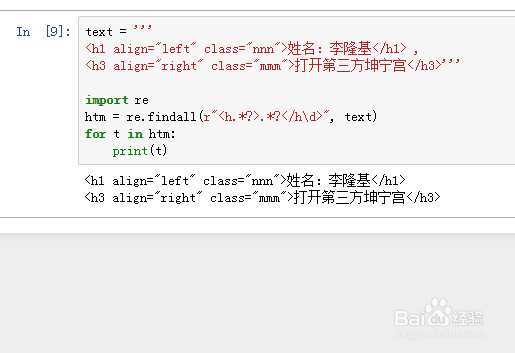
3、或者简单点:
htm = re.findall(r"<h.*?</h\d>", text)

4、用空字符替换内容前面的标签:
k = re.sub("<h.*?>", "", t)
这里的空字符串,指的是没有任何内容,连空格也不要。
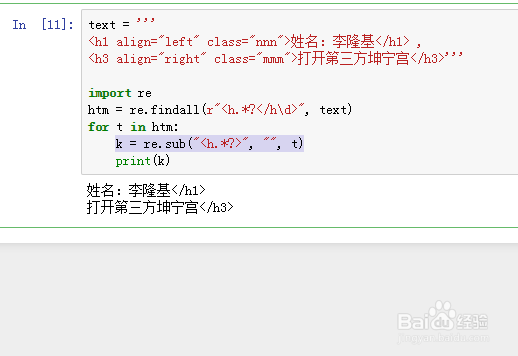
5、再把内容后面的标签去掉,就相当于保留正文内容:
h = re.sub("</h\d>", "", k)

声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:40
阅读量:115
阅读量:68
阅读量:94
阅读量:160