如何快速将纸质文件电子化?
1、(1)打开PDF文件并设置参数
进入Abbyy FineReader软件选择任务后会自动进入下一个界面,此时会自动弹出让你选择文件,如果没有选择文件,则可以在菜单栏中点击“打开”,然后选择你需要转换的文件,注意在文件类型中选择相应的类型,这里应该选择PDF,默认的是图形文件,不更改的话最后得到的是乱码。
打开之后进行基本设置。在菜单栏中选择“工具”中的“选项”,弹出如图2的窗口。

2、(2)文字识别
在所打开的PDF文件中,选择要转换的页面,当然也可以把全部页面或者是页面的部分内容进行转换。这里有两个窗口,一个是转换前的PDF图像页面,另一个是转换后的文本页面。单击PDF图像页面窗口的“读取”选项,进行OCR识别,就是让软件把图片中的文字读取出来(图片中文字越多,识别花费的时间越长,进行识别完成之后,就会在文本页面出现所转换的文本。其中的一些文字带有青色背景底色,这说明这些文字是有可能出现错误的,我们要对它们进行修正,如图3所示。
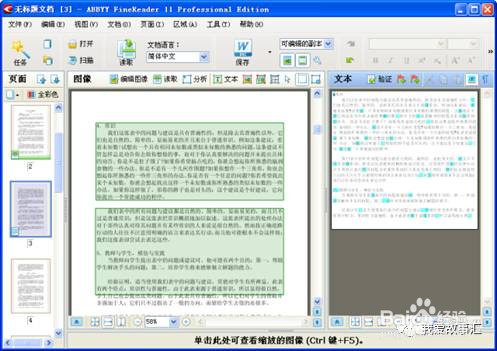
3、(3)文字修正
一般来讲,图片越清晰、对比越鲜明的时候,该软件对文字的识别率就越高。识别率是与图片清晰度、文字大小、文字的端正程度、文字与底色的对比程度有关。Abbyy FineReader的识别率是在所有OCR软件中最好的,基本能在95%以上,当然不能保证100%。为保险起见,还是要人工核对一下识别的结果,尤其是格式特别复杂、有特殊文字和符号的地方是容易出错的。当然如果你用肉眼都看不清楚或者不能分辨的文字,该软件识别出来的可能性是不大的。
该软件的原理是使用扫描的文本字符与系统内置的字符形状、语言辞典进行比较,从而识别文字,只能扫描指定的语言,其他语言不能识别。所以如果错误率太高,则要更改使用的扫描语言。
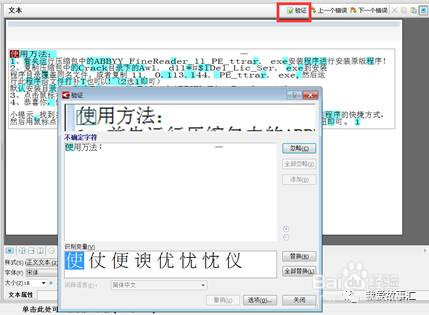
单击文本页面窗口的“验证”选项,此时会弹出验证窗口,如图4所示。在这个窗口中会有一些带有青色背景底色的不确定文字或字符,如果错误的话我们可以直接修改,若是正确则可点击“忽略”跳过。
4、完成修正后就可以保存所转换的文本了,有包括doc/docx在内的10多种保存格式可以选择,一般选择为word97-2003格式或docx格式,完成后就能在word中进行文本编辑了。对于提取jpg、bmp等格式图片中的文字的方法与PDF格式操作大同小异,这里就不再说明。
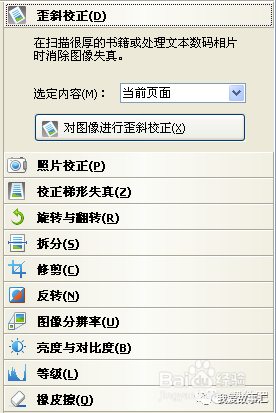
另外提一下的是,如果我们的图片较为模糊或不正,会影响软件对图片文字的读取效果,此时我们就需要用到工具栏中的“编辑图像”进行图像校正。点击“编辑图像”就会弹出图像编辑窗口,如图5所示。我们可以看到右侧有一排工具,用这些工具我们可以对图像进行歪斜校正等多种参数进行编辑修正处理,这样会大大提高图片的识别率。
该软件为绿色版,直接可以使用,以防资源失效,请关注本公众号:我爱故事汇,回复“OCR”即可获得百度云分享链接。