python爬取有道翻译结果,实现即时翻译功能
1、使用chrome浏览器,打开有道翻译页面,输入需要翻译的内容,按f12键
点击翻译按钮后,Network会列出所有的网络请求

2、依次查看每个请求的response,可以看到translate_o?开头的应答中,是我们需要的解析的应答信息
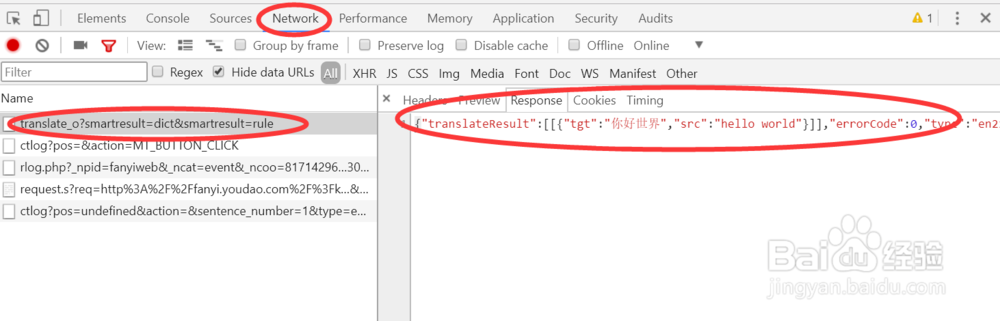
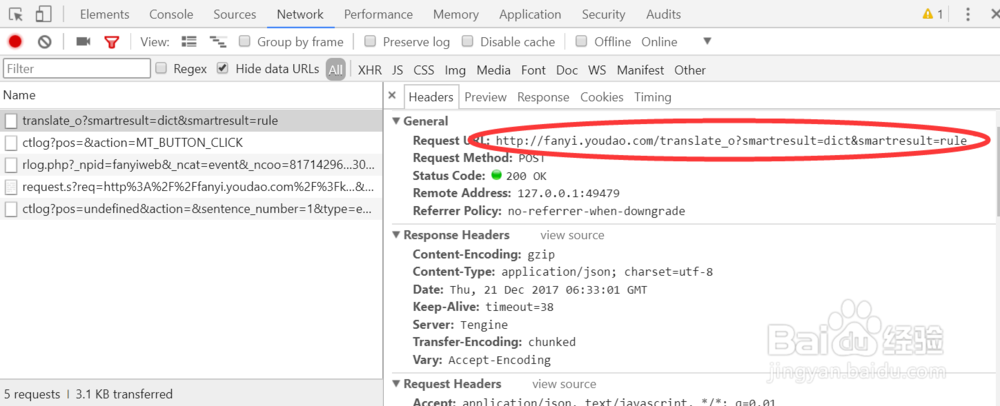
3、查看其对应的Headers,可以看到请求的url,data,用户代理信息
对付防盗链,服务器会识别headers中的referer是不是它自己,如果不是,有的服务器不会响应,所以我们还可以在headers中加入referer
User-Agent是用来模拟浏览器
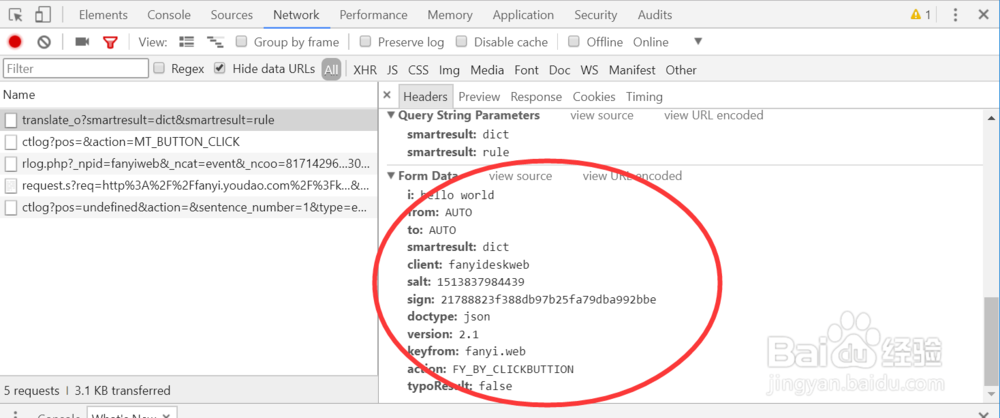
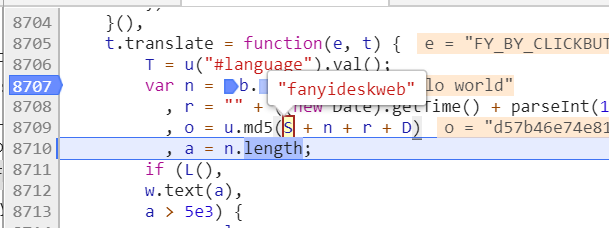
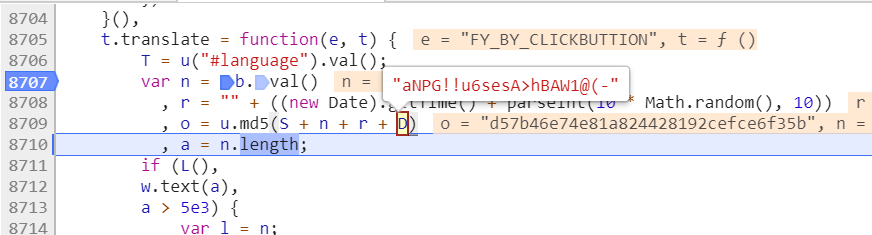
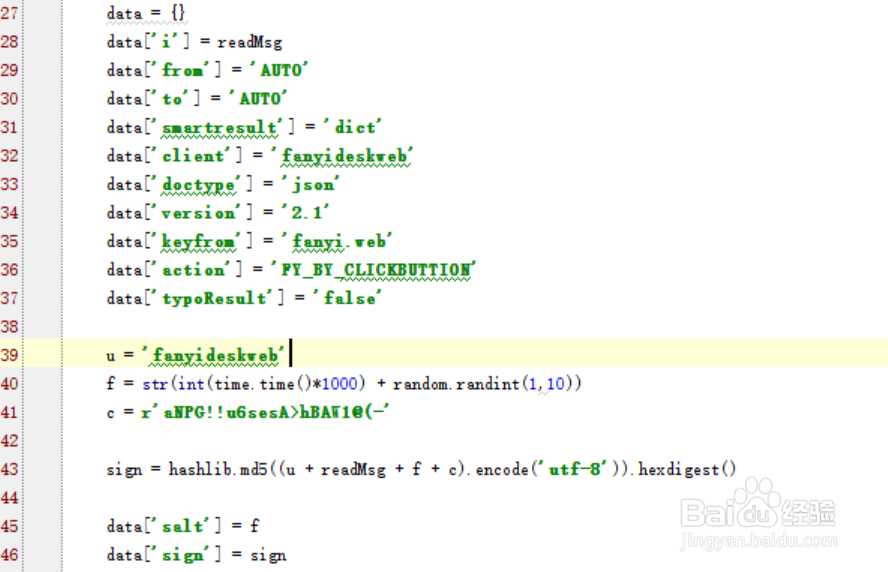
1、数据中的salt和sign是实时变化的,可以通过调试的方法查看盐值算法
2、使用选择箭头,选择翻译按钮,查看按钮点击事件对应的js文件
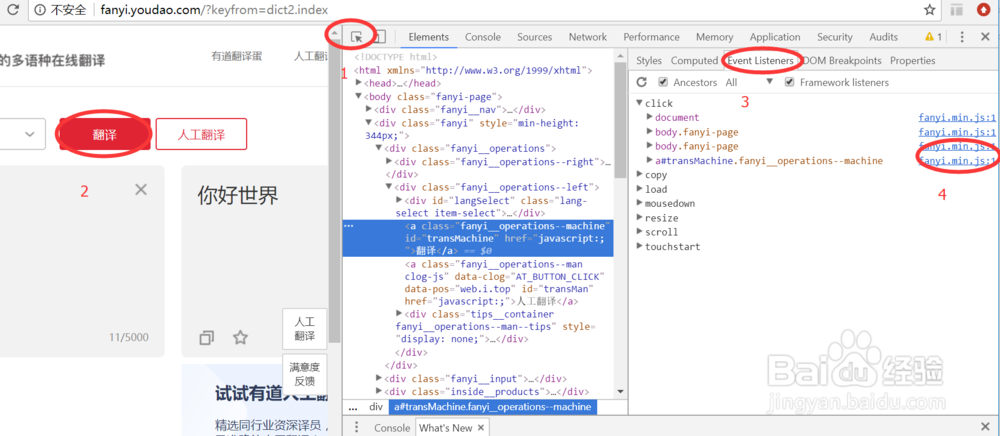
3、点击fanyi.min.js文件,打开文件内容,该文件是没有格式化的,点击左下角的{}按钮,显示格式化后的文件
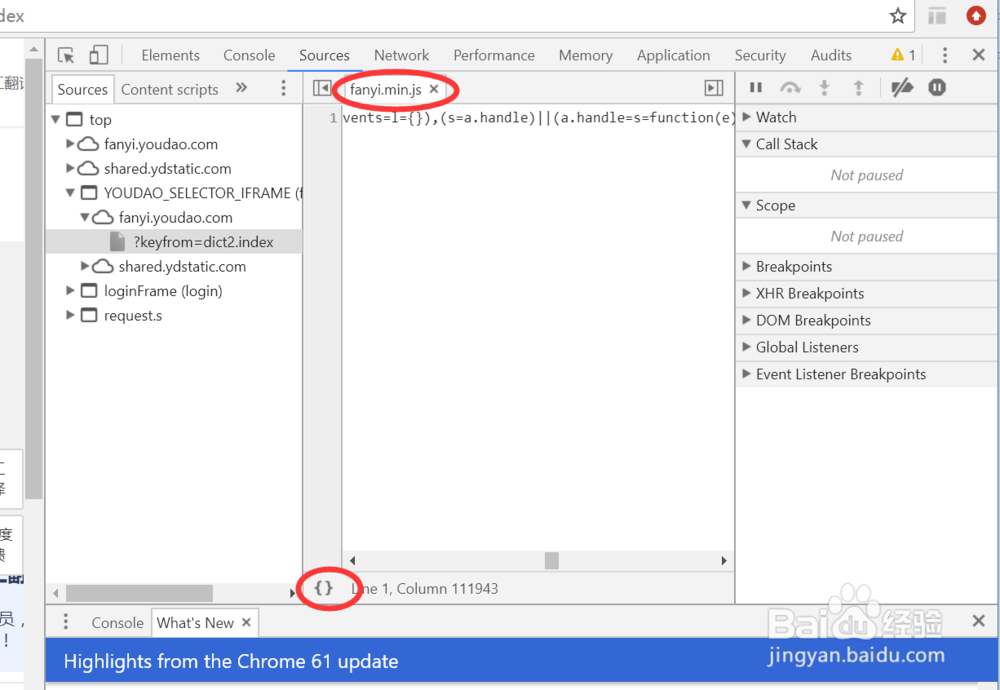
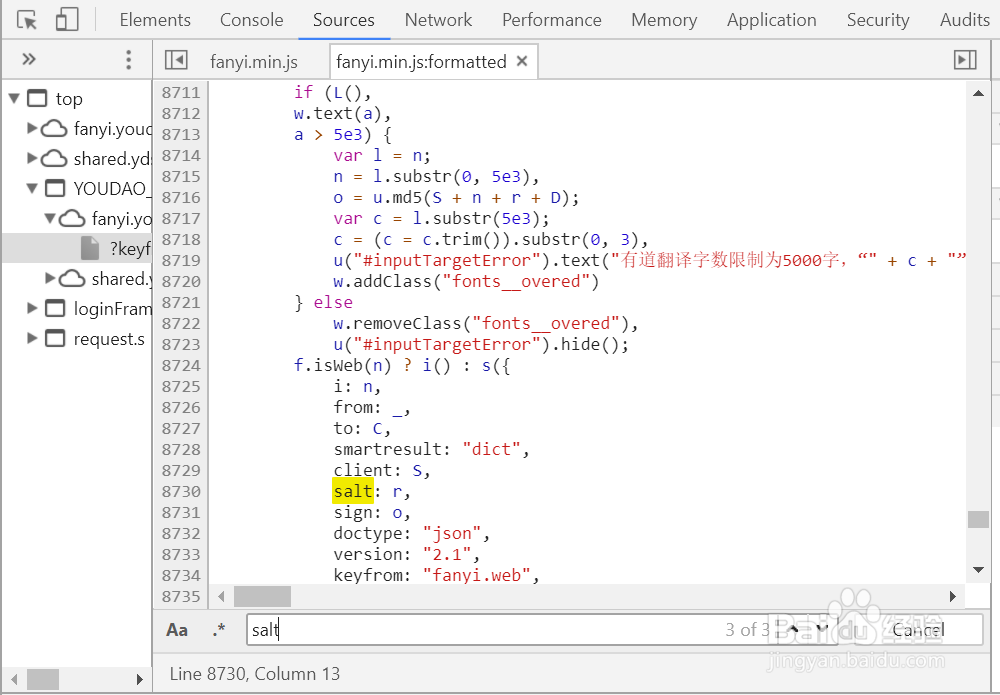
4、在格式化的文件中搜索salt,共搜索到三处,如果不知道具体是哪一个,可以都加上断点来调试。
点击格式话文件左侧的行号,就可以添加断点
5、再次点击页面上的翻译按钮,可以进入断点,然后查看salt是如何计算的
salt是当前时间戳加上一个偏移量
sign是由四部分内容然后计算md5值算出来的
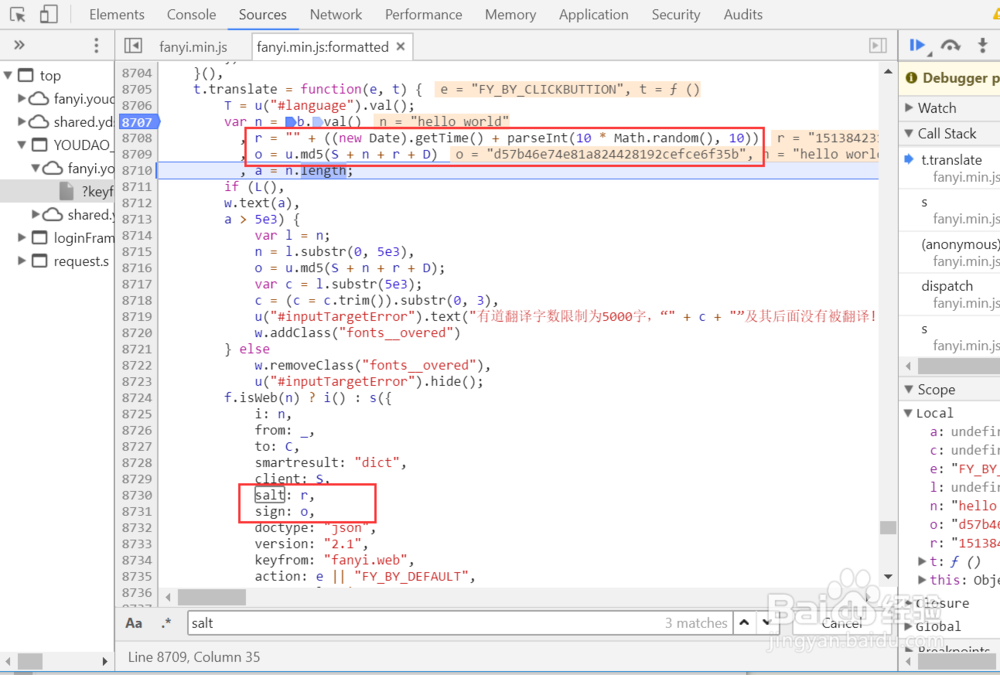
6、这四部分内容中除了一个是salt外,启用内容如下。
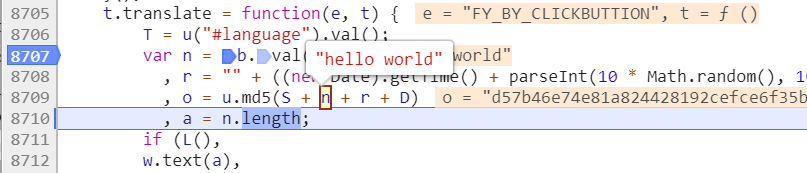
其中n是需要翻译的字符串
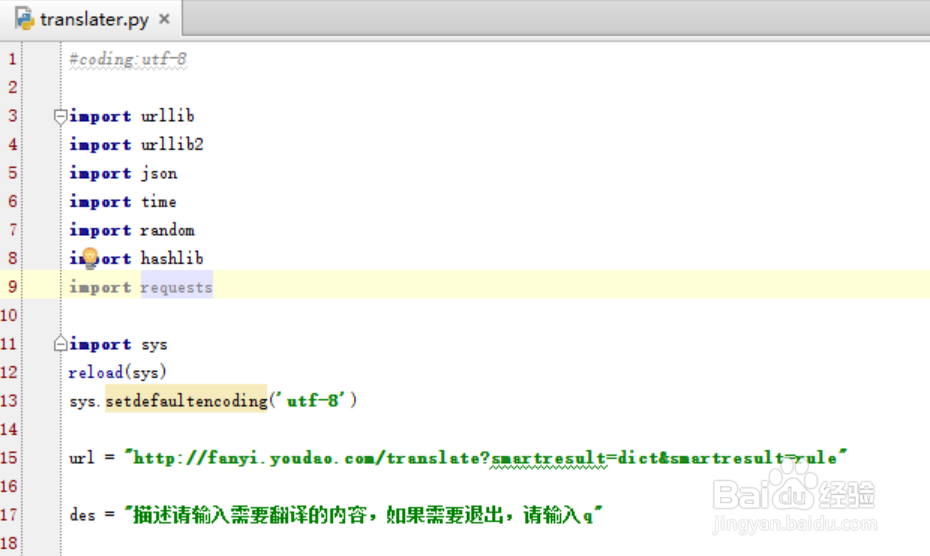
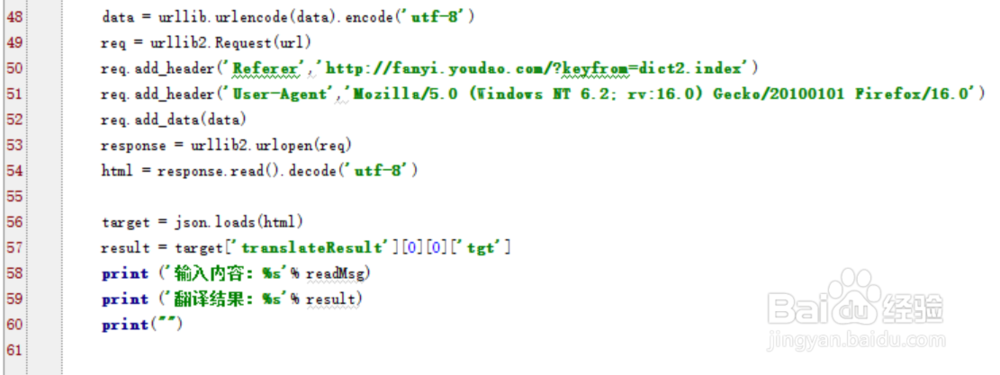
1、引入头文件,及url信息,注意这里url中的translate?中没有_o
如果加上_o就会提示{"errorCode":50}错误。从网上大神那里看到,去掉_o就可以了
2、启动循环,读取用户输入

3、设置data域,使用python生成salt和sign的值
这里需要注意编码格式需要转换成utf-8
4、使用urllib2发起http请求,设置header和数据域
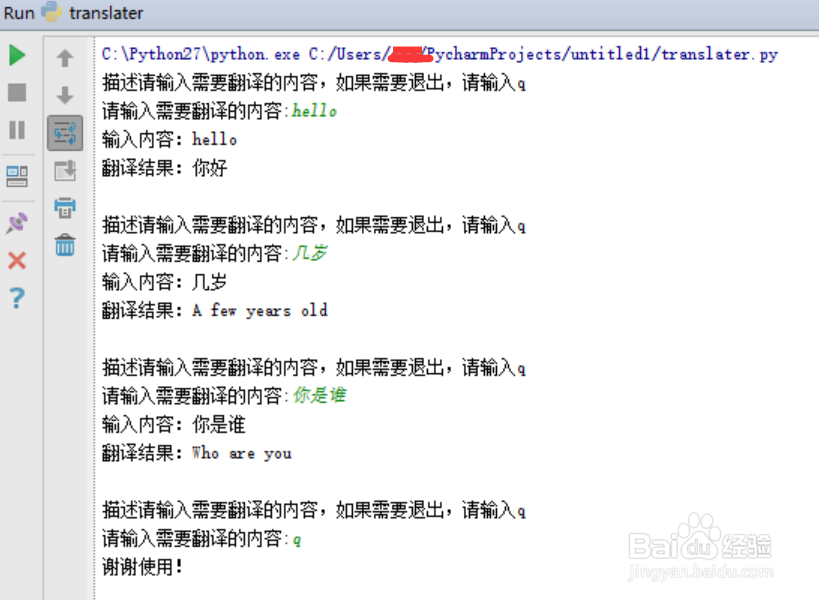
5、运行效果如下
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:153
阅读量:115
阅读量:32
阅读量:46
阅读量:153