ES学习--基于词项term的搜索和基于全文的搜索
1、首先创建一个名称为books的索引,并批量加入多条测试文档数据:
// 删除索引
DELETE books
// 创建索引并批量添加数据
POST /books/_bulk
{"index":{"_id":1}}
{"productId":"Deep Learn Linux", "desc":"Linux"}
{"index":{"_id":2}}
{"productId":"Java Thought", "desc":"Java"}
{"index":{"_id":3}}
{"productId":"Netty Actions", "desc":"Netty"

2、基于词项查询--单个词项匹配查询
基于词项查询的语法结构为:
GET /索引名称/_search
{
"query": {
"term": {
"字段名称":{
"value": "字段值"
}
}
}
}
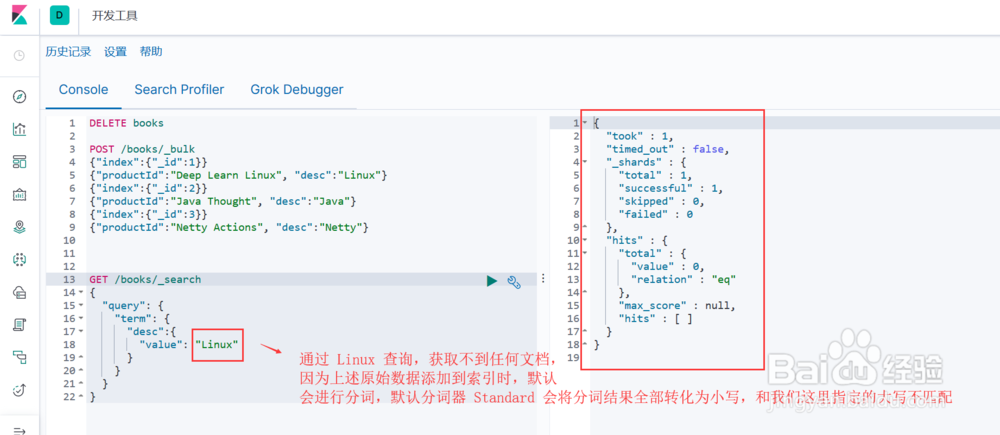
图1示:指定字段desc和值Linux查询,未获取到任何结果,因为原始数据在加入索引时,默认会进行分词处理,默认的分词器会将分词后的所有词项转化为小写,因此通过Linux无法查询到文档数据。
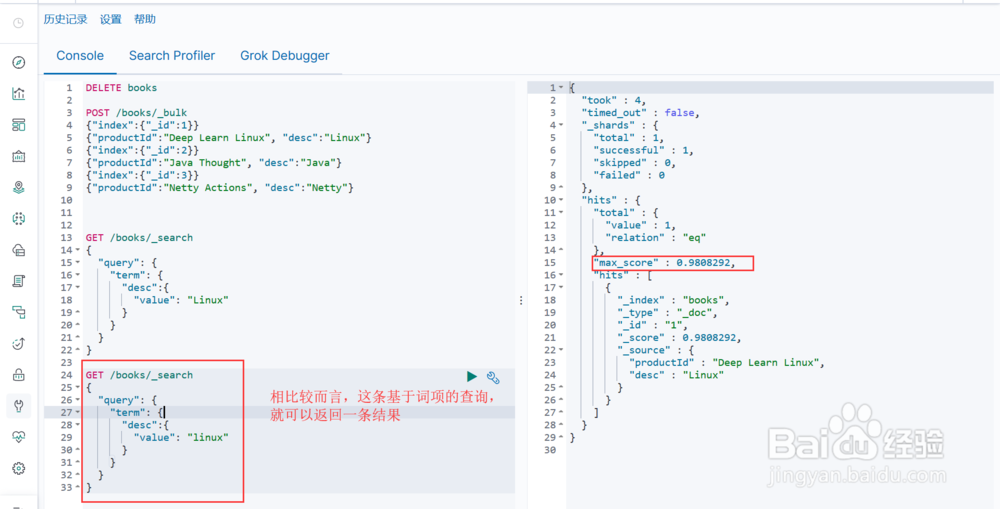
图2示:根据上述的解释,通过 linux 查询就可以得到相应的文档数据。
3、基于词项查询--多个词项的字符串匹配查询
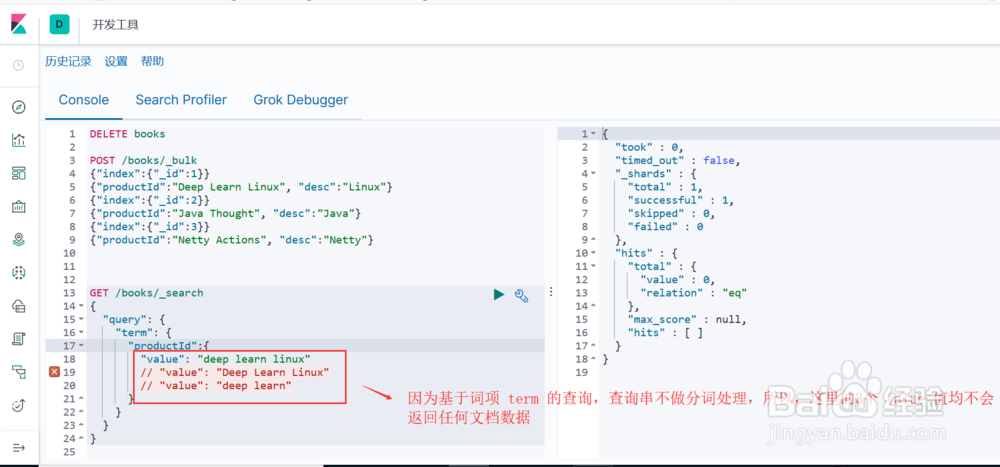
因为基于词项term的查询,查询串不做任何分词处理,因此如果你的查询串中包含多个词项,无论如何查询都不可能匹配到任何文档数据(图1示)。
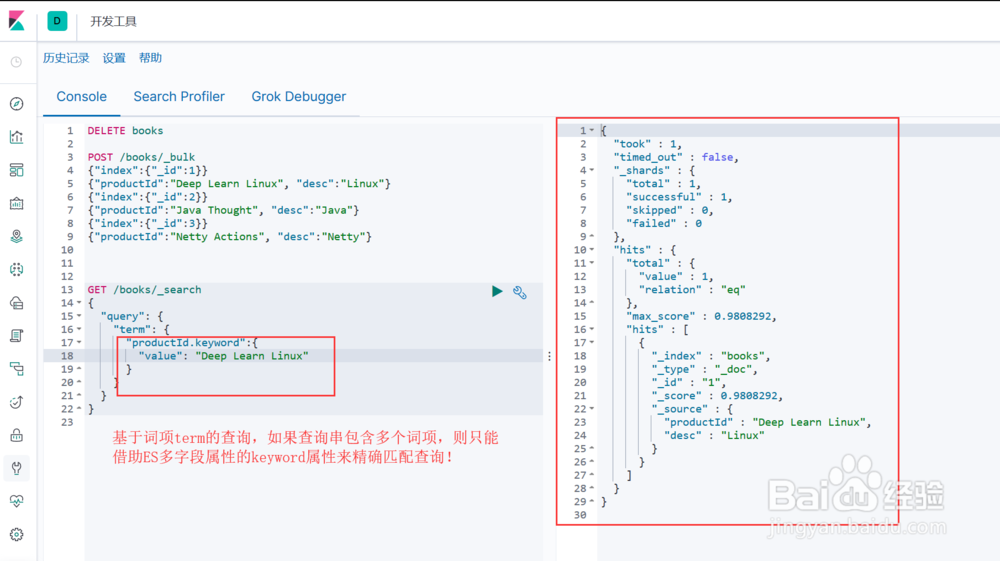
那基于词项term的查询,该如何处理多词项查询串的情况呢?可以记住多字段属性来查询(text类型属性默认有一个keyword字段)(图2示)。
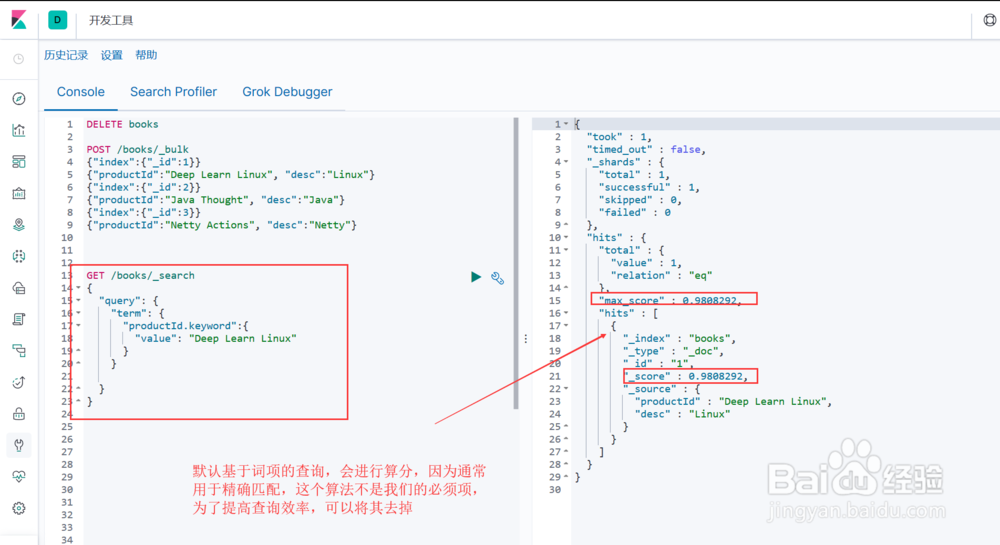
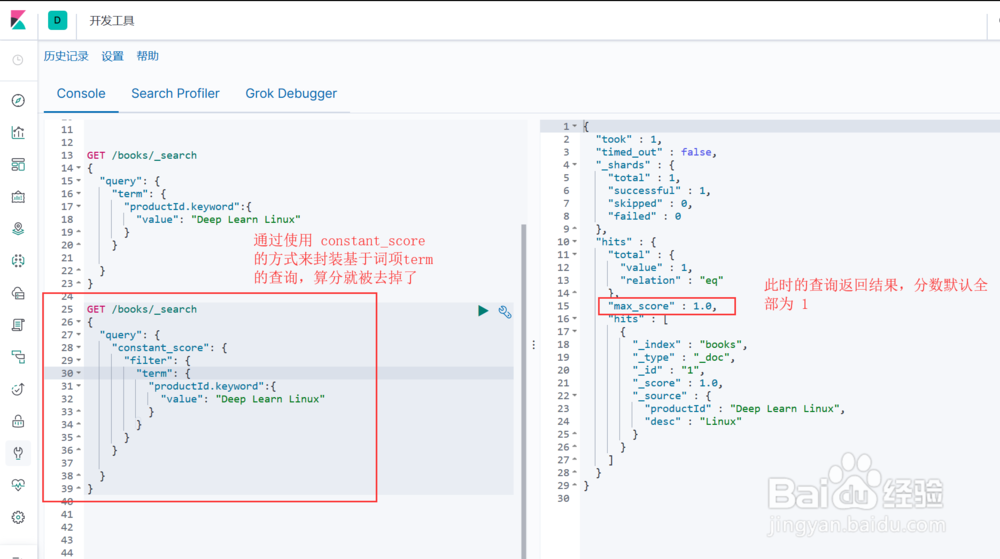
4、基于词项查询--跳过算分查询
对于基于词项的查询,通常用于精确匹配,因此算分数值通常并不关键,可以通过 constant score 将其算分过程去掉,对于大数据量查询,可以提高查询效率!
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:174
阅读量:102
阅读量:150
阅读量:147
阅读量:173