如何利用R软件简单处理文本数据?
1、将要分析的文本文档存在一个目录里。加载程序包tm,利用函数Corpus处理文档。
代码如下:
library(tm)
#读取文件夹名
filename<-"C:/Users/jsb/Desktop/txt"
#语料库,DirSource处理目录
text<-Corpus(DirSource(filename),readerControl = list(language="lat"))
summary(text)
要处理的目录中有两个文档,文档名称和类别。
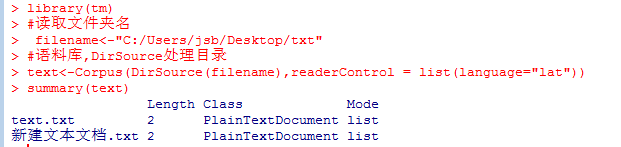
2、读取文档目录后,可以用函数inspect查看文档,查看单个文档要加双括号。
#语料库的提取
inspect(text[1:2])
#提取单个文档
identical(text[[1]],text[["text.txt"]])
text[[1]]

3、利用tm_map函数对文本进行一些处理。
#去除空白
text<- tm_map(text, stripWhitespace)
#小写变换
text<-tm_map(text,tolower)
#停止词去除
text<-tm_map(text,removeWords,stopwords("english"))

4、wordcloud包中的wordcloud函数绘制词云图。
#词云图
> library(wordcloud)
> wordcloud(text)
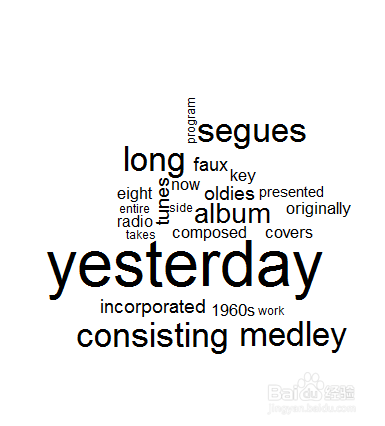
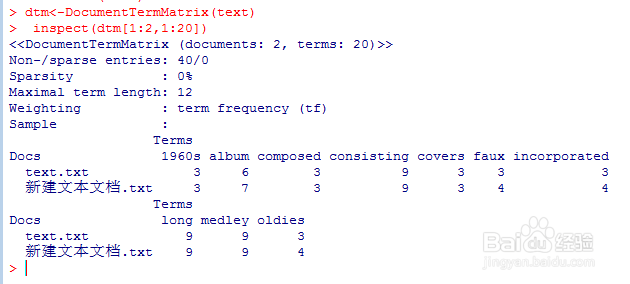
5、利用DocumentTermMatrix 生成文档关系矩阵,这是建立模型的基础。
#文档关系矩阵
dtm<-DocumentTermMatrix(text)
inspect(dtm[1:2,1:20])
结果中可以看到前两个文档中20个词语出现的频次表。
6、从文档关系矩阵出找出我们关心的词。
例如:
#找出出现6次以上的条目
findFreqTerms(dtm,6)
#找到与"program"的相关系数在0.8以上的条目
findAssocs(dtm, "program", 0.8)
