elasticsearch学习六、完全匹配搜索、精确匹配
1、先看下NGram分词器属性
min_gram:单个词的最小长度,默认1
max_gram:但歌词的最大长度,默认2
token_chars:大概就是es会按照不在列表中的字符集合进行文本分割(具体意思大家看图原文^_^)

2、token_chars 字符classes:
letter for example a, b, ï or 京
digit for example 3 or 7
whitespace for example " " or "\n"
punctuation for example ! or "
symbol for example $ or √

3、先看个example,
curl -XPUT 'localhost:9200/test' -d '
{
"settings" : {
"analysis" : {
"analyzer" : {
"my_ngram_analyzer" : {
"tokenizer" : "my_ngram_tokenizer"
}
},
"tokenizer" : {
"my_ngram_tokenizer" : {
"type" : "nGram",
"min_gram" : "2",
"max_gram" : "3",
"token_chars": [ "letter", "digit" ]
}
}
}
}
}'

4、看下这个的分词效果
curl 'localhost:9200/test/_analyze?pretty=1&analyzer=my_ngram_analyzer' -d '中华人民共和国'
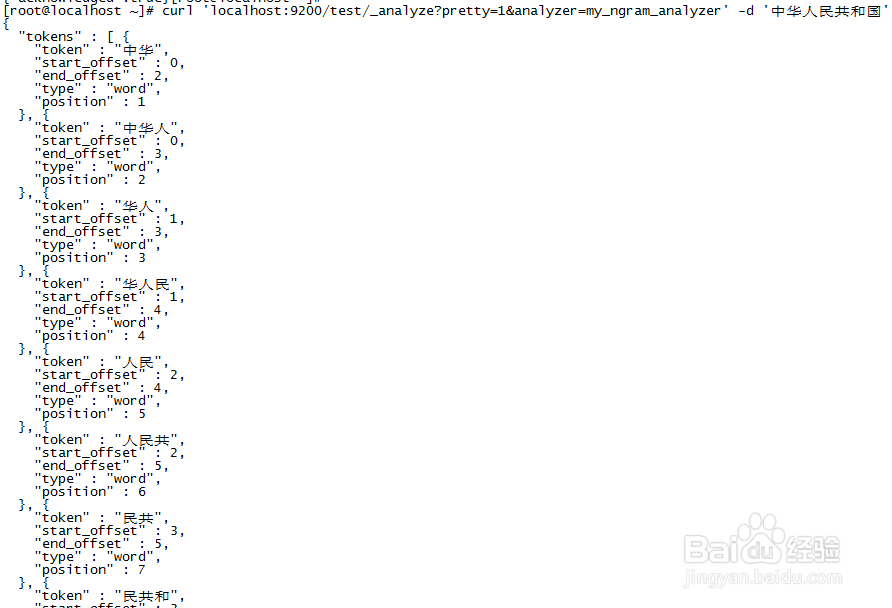
1、定义一个charsplit的分析器,使用的ngram分词。min_gram、max_gram为1,同时我只需要匹配letter、digit、punctuation。
curl -XPUT 'localhost:9200/dm_v1' -d '{
"settings": {
"analysis": {
"analyzer": {
"charSplit": {
"type": "custom",
"tokenizer": "ngram_tokenizer"
}
},
"tokenizer": {
"ngram_tokenizer": {
"type": "nGram",
"min_gram": "1",
"max_gram": "1",
"token_chars": [
"letter",
"digit",
"punctuation"
]
}
}
}
}
}'

2、接下来创建mapping,可以参考我前面的学习四里面创建mapping,指定分析器为前面一步中定义的


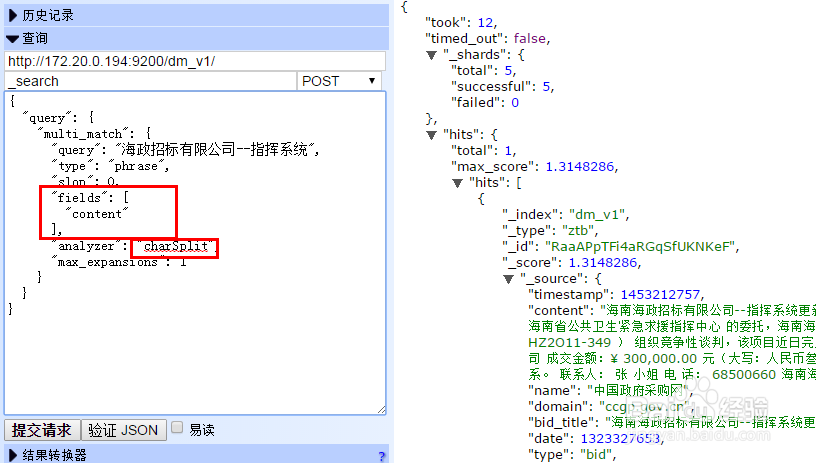
3、接下来使用完全匹配查询试试啦.只出一条完全匹配的数据,搞定!
{
"query": {
"multi_match": {
"query": "query_string",
"type": "phrase",
"slop": 0,
"fields": [
"content"
],
"analyzer": "charSplit",
"max_expansions": 1
}
}
}
4、最后记录一个组合的多条件查询
要求:查出样本1中,内容或者url或标题包含‘new’的所有记录。
需要注意的是fields中的属性include_in_all都是true的,这样_all才能对该字段搜索
{"query":{
"bool":
{"must":[{"term":{"sample":1}},{
"multi_match": {
"query": "new",
"type": "phrase",
"slop": 0,
"fields": [
"content","url","bid_title"
],
"analyzer": "charSplit",
"max_expansions": 1
}
}]}
}
}
