DataFrame的层次化索引、分级排序
1、前提:加载numpy,pandas和Series,DataFrame。
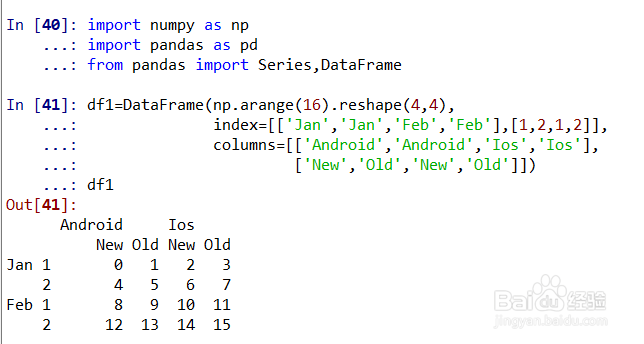
生成一个每条轴都有层次索引的DataFrame,命名为df1,如图
2、对各层索引指定名称,如“key1”、“key2”及轴标签“OS”、“version”,如图所示

3、选取DataFrame的列分组。
如df1['Ios']表示选取Ios的数据,如图

4、如何创建一个可以服用的MultiIndex呢?
这里需要用cn=pd.MultiIndex.from_arrays([轴标签],[索引名称])
,具体如图

5、针对多层次索引,互换两个轴索引如何操作呢?
df1.swaplevel('key1','key2')表示将这2个索引互换位置;
df1.sortlevel(1)和df1.sort_index(level=1)表示按key2的值升序排列;
df1.swaplevel(0,1).sort_index(level=0)则表示先互换,再排序;
如图



6、DataFrame按级别汇总数据。
例如:df1.sum(level='key2')表示按key2对列进行求和;
df1.sum(level='OS',axis=1)表示按OS对行进行求和;
如图


声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:46
阅读量:84
阅读量:47
阅读量:169
阅读量:39