requests得到的怎么转换成html
1、这里用sublime text 3 作为示范,首先要创建一个py文档。

2、import requests
第一步要引入模块,这是第三方库,如果没有安装需要用pip install requests来安装。

3、result = requests.get("网页地址")
这里我们首先要用一个变量存储获取到的网页,方便进行下一步的操作。

4、result.raise_for_status()
加上这一句,防止如果网页打不开的情况,比如404。

5、print(result)
这里打印变量,可以看到是200,这就是可以正确访问网页,并且可以存储。

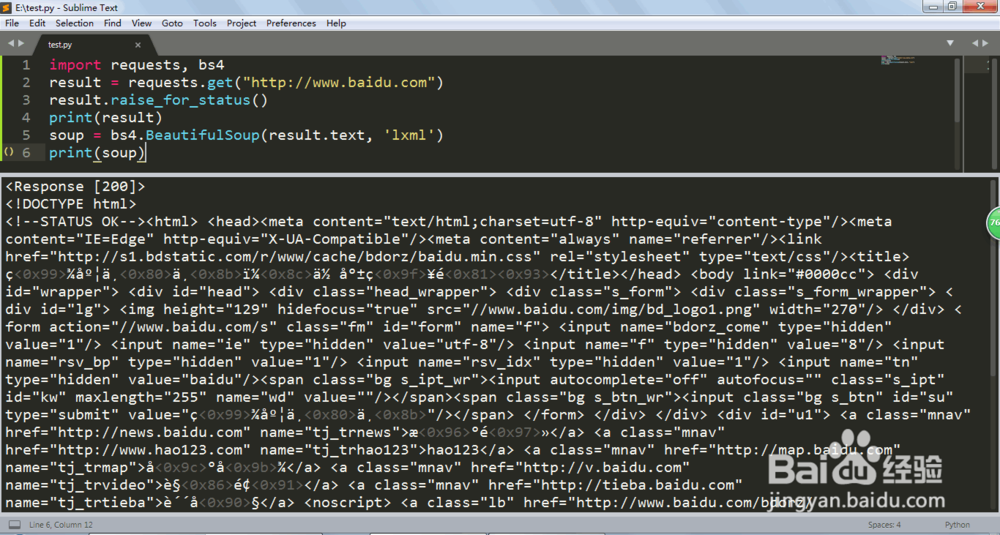
6、import requests, bs4
soup = bs4.BeautifulSoup(result.text, 'lxml')
再引入一个第三方库bs4,然后进行网页解析。
这个时候打印一下就能得到html了。
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:150
阅读量:129
阅读量:193
阅读量:74
阅读量:20