怎么爬取微博数据
1、找出微博用户唯一标示:oid
点开右边的network选项,在里面选中xhr,并滑动页面的滚动条加载出新页面,此时会出现一个表单,点击该表单。
2、from urllib.parse import urlencode
import requests
from pyquery import PyQuery as pq
import time
from pymongo import MongoClient
base_url = 'https://m.weibo.cn/api/container/getIndex?'
headers = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/2830678474',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
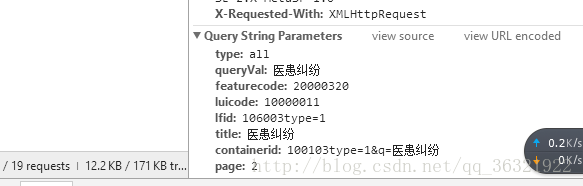
def get_page(page): #得到页面的请求,params是我们要根据网页填的,就是下图中的Query String里的参数
params = {
'containerid': '100103type=1&q=杀医',
'page': page,#page是就是当前处于第几页,是我们要实现翻页必须修改的内容。
'type':'all',
'queryVal':'医患纠纷',
'featurecode':'20000320',
'luicode':'10000011',
'lfid':'106003type=1',
'title':'医患纠纷'
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(page)
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)

3、获取到页面就到了最麻烦的解析页面的环节了,因为ajax返回的是json格式,所以用pyquery特别方便,这一部分需要具体分析获得json结构,我的经验是先如果嵌套在字典里就用.get()方法,如果内容在list里,就用for循环,最终可以发发现,我们要获取的内容先大致是这样