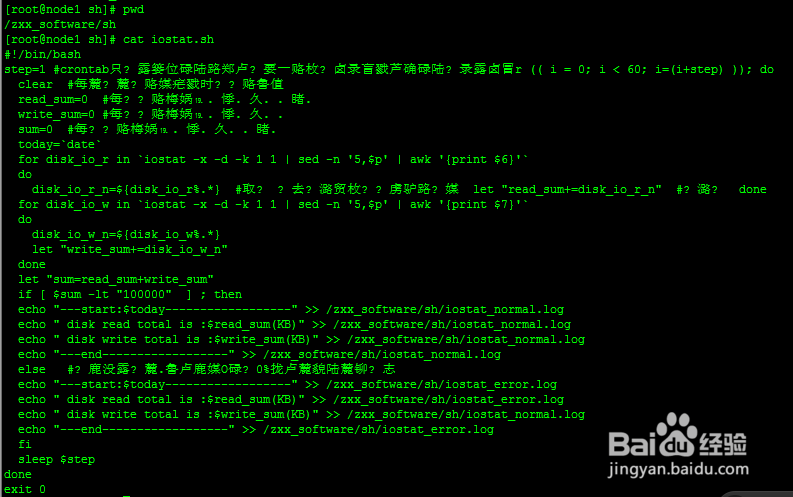
统计iscsi或者光纤存储磁盘IO情况
1、1、创建目录
mkdir -p /zxx_software/sh
2、2、编辑iostat.sh脚本
#!/bin/bash
step=1 #crontab只能定位到分,需要一个休眠时间来精确到秒级别
for (( i = 0; i < 60; i=(i+step) )); do
clear #每次执行该脚本时重新赋值
read_sum=0 #每秒钟各个存储逻辑卷的总读取量
write_sum=0 #每秒钟各个存储逻辑卷的总写量
sum=0 #每秒钟各个存储逻辑卷的总读写量
today=`date`
for disk_io_r in `iostat -x -d -k 1 1 | sed -n '5,$p' | awk '{print $6}'`
do
disk_io_r_n=${disk_io_r%.*} #取整 舍去最后一个.及其右部分数据
let "read_sum+=disk_io_r_n" #求和
done
for disk_io_w in `iostat -x -d -k 1 1 | sed -n '5,$p' | awk '{print $7}'`
do
disk_io_w_n=${disk_io_w%.*}
let "write_sum+=disk_io_w_n"
done
let "sum=read_sum+write_sum"
if [ $sum -lt "100000" ] ; then
echo "---start:$today------------------" >> /zxx_software/sh/iostat_normal.log
echo " disk read total is :$read_sum(KB)" >> /zxx_software/sh/iostat_normal.log
echo " disk write total is :$write_sum(KB)" >> /zxx_software/sh/iostat_normal.log
echo "---end------------------" >> /zxx_software/sh/iostat_normal.log
else #如果磁盘读写总量超过带宽IO的80%,打印到错误日志
echo "---start:$today------------------" >> /zxx_software/sh/iostat_error.log
echo " disk read total is :$read_sum(KB)" >> /zxx_software/sh/iostat_error.log
echo " disk write total is :$write_sum(KB)" >> /zxx_software/sh/iostat_normal.log
echo "---end------------------" >> /zxx_software/sh/iostat_error.log
fi
sleep $step #睡眠1秒
done
exit 0
3、3、赋予脚本执行权限
[root@node1 sh]# pwd
/zxx_software/sh
[root@node1 sh]# chmod +x iostat.sh

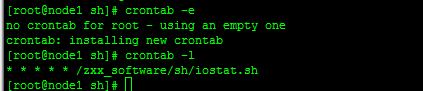
4、4、设置定时任务
* * * * * /zxx_software/sh/iostat.sh
每天每分钟执行一次脚本
注意:
1、crontab 定时只能精确到分钟
2、编辑crontab之后,不会立即生效,缓冲时间1分钟。
5、5、参数解析
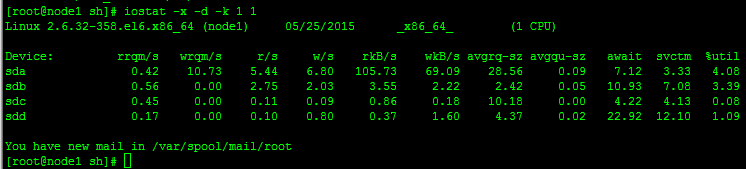
iostat -x -d -k 1 1 命令参数解析:
第一个1表示 一秒钟刷新一次磁盘IO情况,
第二个1表示 只刷新一次
其磁盘IO内容参数解析:
rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge);wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。
rsec/s:每秒读取的扇区数;
wsec/:每秒写入的扇区数。
rKB/s:The number of read requests that were issued to the device per second;
wKB/s:The number of write requests that were issued to the device per second;
avgrq-sz 平均请求扇区的大小
avgqu-sz 是平均请求队列的长度。毫无疑问,队列长度越短越好。
await: 每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。
这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
svctm 表示平均每次设备I/O操作的服务时间(以毫秒为单位)。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长, 系统上运行的应用程序将变慢。
%util: 在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度
。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
6、6、磁盘IO极端对比
拿 磁盘读写总数*8 去和带宽1GB比较
可以发现当磁盘读写总数*8大于1GB时,磁盘util达到100%,此时存储的IO肯定是有问题的,需要处理。
原因可能是:某个应用对含有blob字段的表进行频繁的全表扫描


