如何使用Scrapy爬取微信公众号的文章列表及链接
1、使用Scrapy命令创建爬虫的基本框架代码
scrapy startproject wechatFishman

2、使用Scrapy命令生存爬虫的的主类文件
scrapy genspider wechatFishman mp.weixin.qq.com

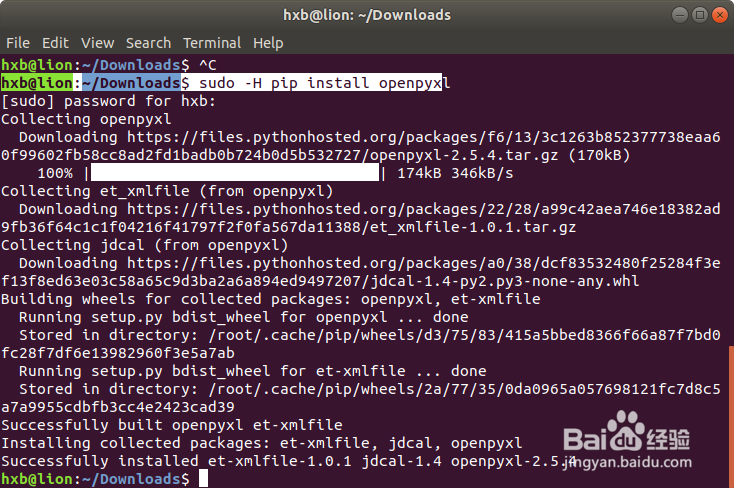
1、安装python Excel处理包
使用如下命令进行安装:
sudo -H pip install openpyxl
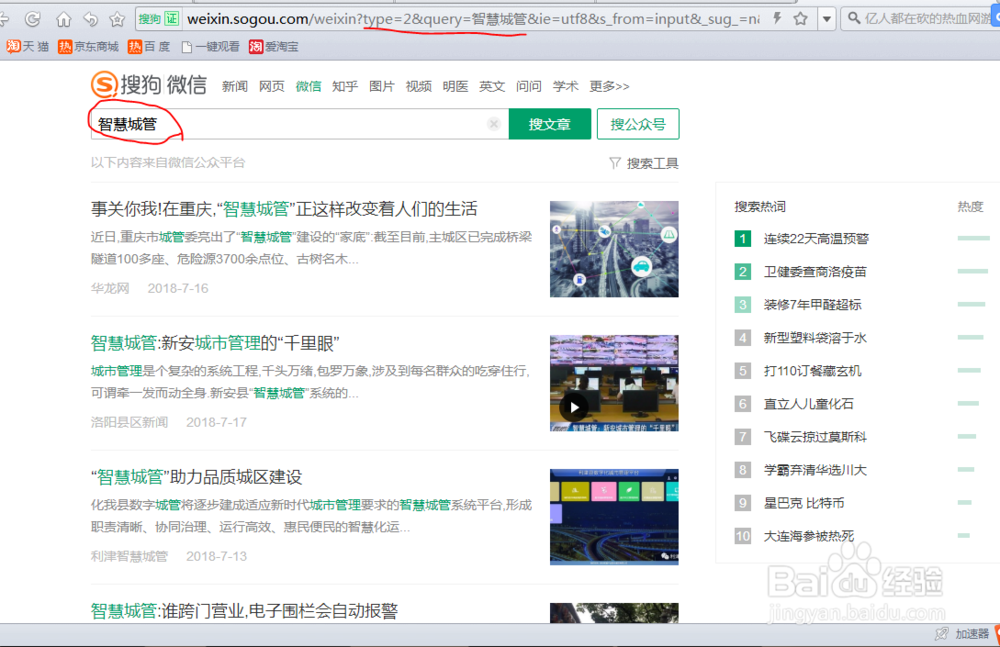
1、打开搜狗选择微信搜索选项进行搜索
在搜索栏输入“智慧城管”关键词进行搜索,我们就可以看到在微信上的相关文章列表
2、搜索网址爬取策略分析
1. 搜索URL需要带Type 参数:微信搜索时type =2
2. 搜索URL的关键词query参数:网址中我们可以直接将搜索关键词作为query的参数
3. 在进行爬虫时可以不需要其他参数
分析后我们在爬虫中需要访问的URL连接样例如下:
http://weixin.sogou.com/weixin?type=2&query=智慧城管
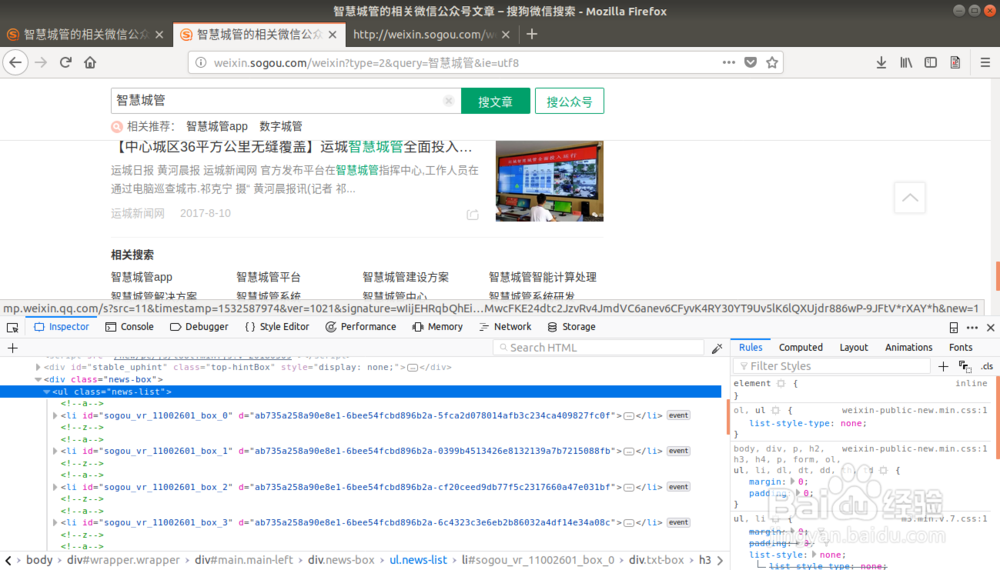
3、搜索结果爬取策略分析
1. 上一个步骤我们得到一个查询结果的页面
2. 查看查询结果页面的源代码,可以发现文章列表都在
<ul class="news-list"> </ul>里面
3.文章列表css定位:
<div class="txt-box">内的<a>元素中
所以我们可以通过 ul -> div ->a 的顺序定位文章的列表以及连接
4、搜索结果下一页的爬取策略分析
1.下一页的按钮对应的源代码如下:
<a id="sogou_next" href="?query=%E6%99%BA%E6%85%A7%E5%9F%8E%E7%AE%A1&_sug_type_=&sut=2307&lkt=1%2C1533556190561%2C1533556190561&s_from=input&_sug_=n&type=2&sst0=1533556190663&page=2&ie=utf8&w=01019900&dr=1" class="np" uigs="page_next">下一页</a>
2. 我们可以共同 <a id="sogou_next">进行定位,找到下一页的URL地址进行爬取

1、WechatfishSpider.py 主文件
# -*- coding: utf-8 -*-
import scrapy
from wechatFishman.items import WechatfishmanItem
from selenium import webdriver
from bs4 import BeautifulSoup as bs4
import time
import wechatFishman.settings as settings
class WechatfishSpider(scrapy.Spider):
name = 'wechatFish'
key_word=settings.SUBJECT_KEY_WORDS
allowed_domains = ['mp.weixin.qq.com','weixin.sogou.com','mmbiz.qpic.cn']
start_urls = ['http://weixin.sogou.com/weixin?type=2&query=%s&ie=utf8' %key_word]
def parse(self, response):
print("\n")
print("***********parse spider***************")
wechat_item = WechatfishmanItem()
driver = webdriver.PhantomJS()
driver.get(response.url)
#time sleep is very import to load the url
time.sleep(30)
soup = bs4(driver.page_source,'html.parser')
news_list=soup.find_all('ul', {'class':'news-list'})
for news_item in news_list:
txt_box_list = news_item.find_all('div', {'class':'txt-box'})
for txt_box in txt_box_list:
news_href=txt_box.find('a')
wechat_item["file_name"] = news_href.get_text().strip()
print("******************\n")
print("title :%s" % wechat_item["file_name"])
wechat_item["file_url"] = news_href.get("href")
print("href :%s" % wechat_item["file_name"])
yield wechat_item
#for prevision page
next_page=soup.find('a',{"id":'sogou_next'})
if next_page:
if len(next_page) == 0:
print("\n-------->Finished the spider")
return
next_page_link = next_page.get("href")
if next_page_link:
#the last element
next_page_link = "http://weixin.sogou.com/weixin"+ next_page_link
yield scrapy.Request(next_page_link, callback=self.parse)
else:
print("\n-------->No More Page")
driver.quit()

2、WechatfishmanItem.py:爬取结果项定义类
import scrapy
class WechatfishmanItem(scrapy.Item):
# define the fields for your item here like:
file_name = scrapy.Field()
file_url = scrapy.Field()
3、settings.py 打开中间件以及配置相关的常量值
FILE_SAVE_DIR='/home/hxb/wechat'
SUBJECT_FILE_NAME='深度学习'
SUBJECT_KEY_WORDS='深度学习'
ITEM_PIPELINES = {
'wechatFishman.pipelines.WechatfishmanPipeline': 1,
}
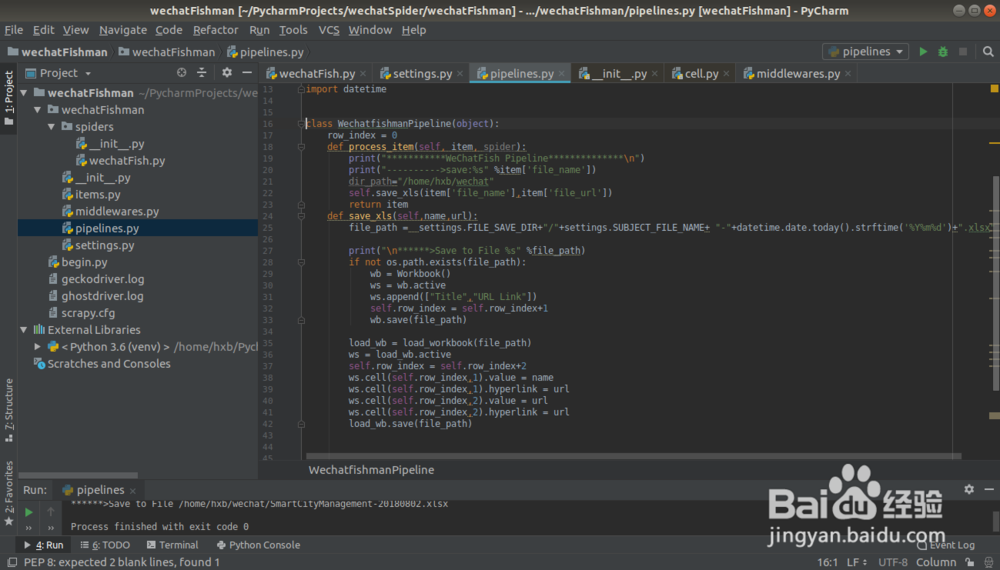
4、爬取结果处理类:WechatfishmanPipeline
# -*- coding: utf-8 -*-
import wechatFishman.settings as settings
from openpyxl import Workbook
from openpyxl import load_workbook
import os
import datetime
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from scrapy.xlib.pydispatch import dispatcher
from scrapy import signals
class WechatfishmanPipeline(object):
row_index = 0
file_path = settings.FILE_SAVE_DIR+"/"+settings.SUBJECT_FILE_NAME+ "-"+datetime.date.today().strftime('%Y%m%d')+".xlsx"
def __init__(self):
dispatcher.connect(self.spider_closed,signals.spider_closed)
def process_item(self, item, spider):
print("***********WeChatFish Pipeline**************\n")
print("---------->save:%s" %item['file_name'])
dir_path="/home/hxb/wechat"
self.save_xls(item['file_name'],item['file_url'])
return item
def spider_closed(self,spider):
print("\n--------------->closed spider")
self.send_mail(self.file_path)
def save_xls(self,name,url):
print("\n******>Save to File %s" %self.file_path)
if not os.path.exists(self.file_path):
wb = Workbook()
ws = wb.active
ws.append(["Title","URL Link"])
self.row_index = self.row_index+1
wb.save(self.file_path)
load_wb = load_workbook(self.file_path)
ws = load_wb.active
self.row_index = self.row_index+1
ws.cell(self.row_index,1).value = name
ws.cell(self.row_index,1).hyperlink = url
ws.cell(self.row_index,2).value = url
ws.cell(self.row_index,2).hyperlink = url
load_wb.save(self.file_path)
def send_mail(self,file):
mail_host = 'smtp.163.com'
msg = MIMEMultipart('related')
msg['Subject'] = 'WeChat Spider result from'
msg['From'] = 'aaa@163.com'
#to_list = ['xxx@xxx.com','aaa@bbb.com','ccc@sss.com']
to_list= ['xxx@aaa.com']
msg['To']=','.join(to_list)
msg_doc = MIMEText(open(file,'rb').read(),'base64','utf8')
msg_doc.add_header('content-disposition','attachment',filename=settings.SUBJECT_FILE_NAME+datetime.date.today().strftime('%Y%m%d')+".xlsx")
msg.attach(msg_doc)
smtp = smtplib.SMTP(mail_host,25)
smtp.login('aaa@163.com','vicent$1981')
smtp.sendmail('aaa@163.com','aaa@ccc.com',msg.as_string())
smtp.quit()
1、使用scrapy命令运行创建的爬虫:
scrapy crawl wchatFish
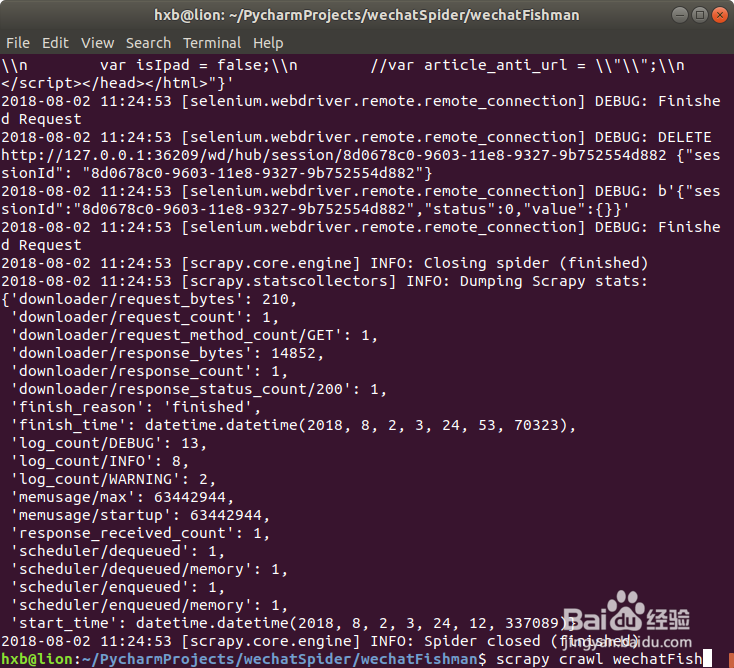
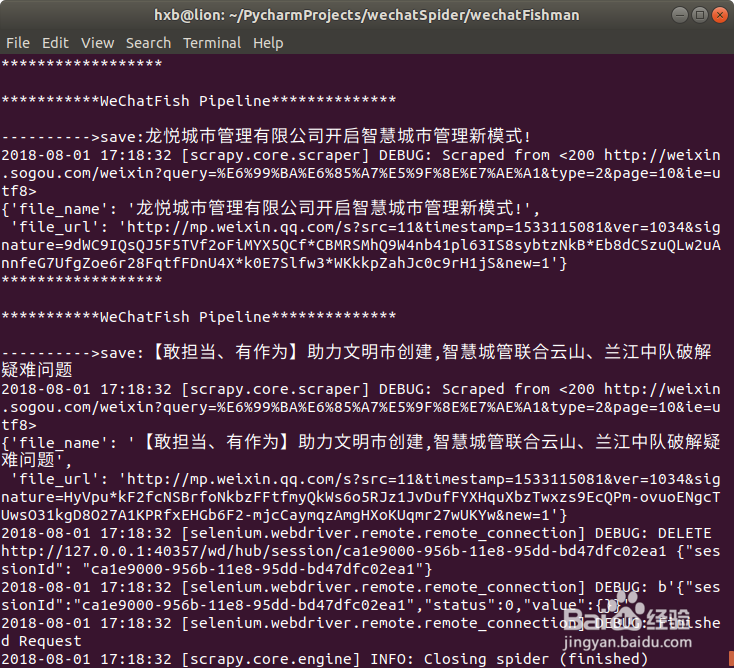
2、查看爬虫结果
在我们设定的目录可以看到生成的爬虫文件
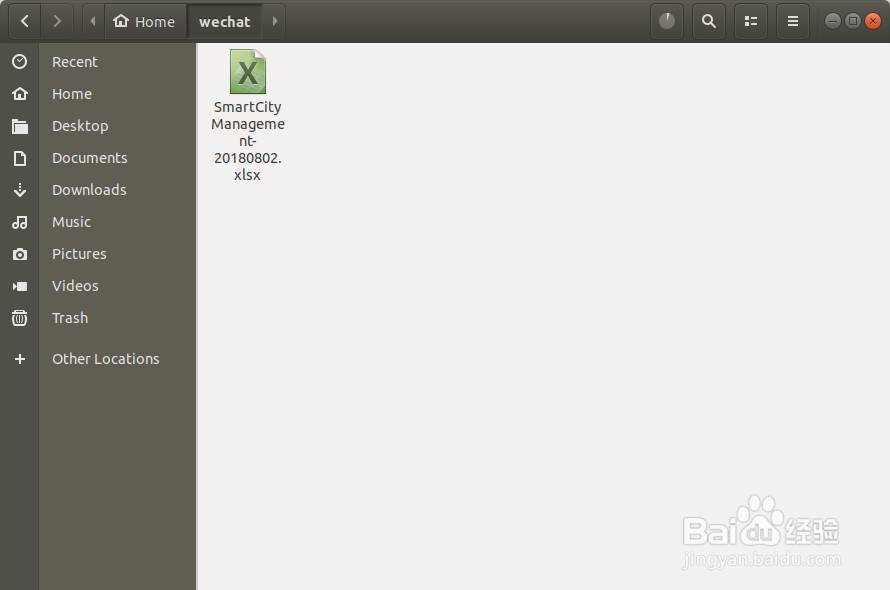

3、在邮箱中我们也可以到爬虫发送过来的excel结果文件