Python读取网页上的pdf文件,输出字符串
1、首先安装pdf文件python读沫袭取包,
PDFMiner
PDFMiner是一种从PDF文档中提取信息的工具。与其他PDF相关工具不同,它完全专注于获取和分析文本数据。
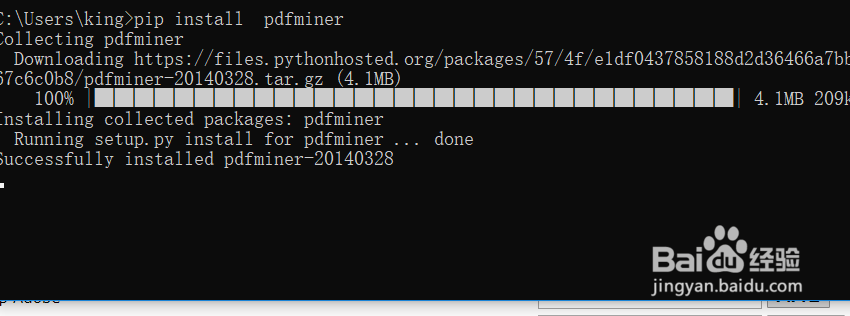
如下所示 pip install PDFMiner
2、开始使用PDFMiner来读取一个远程的pdf文件,除了使用PDFMiner,还需要安装urllib 或者urllib2,有时候这些都安装了,在导入process_pdf的时候会找不到,这个时候就需要重新安装 pdfminer
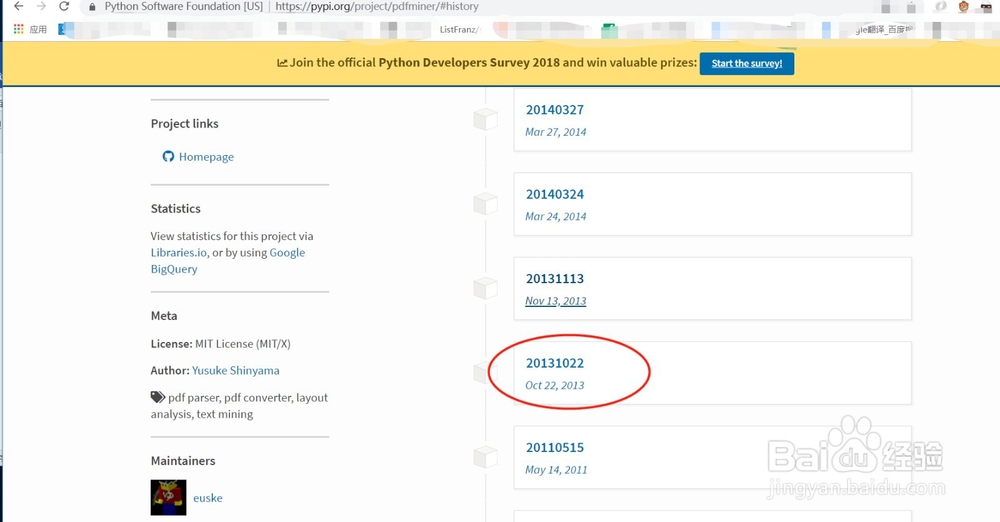
可以到如下地址寻找 pdfminer的历史版本,例如我这里安装pdfminer 20131022
pip install pdfminer==20131113
安装完成后如下所示 process_pdf可以导入正常使用了,好的我们开始下一步
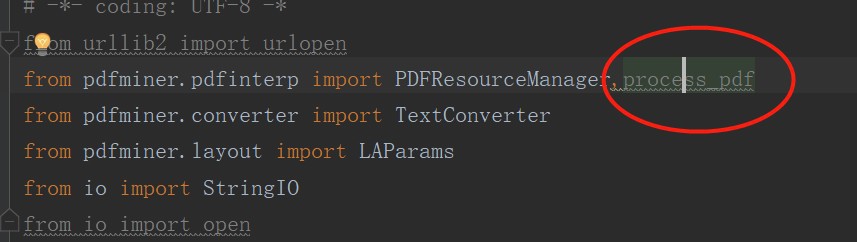
3、读取一个远程的pdf文件,输出字符串
# -*- coding: UTF-8 -*from urllib import urlopenfrom pdfminer.pdfinterp import PDFResourceManager, process_pdffrom pdfminer.converter import TextConverterfrom pdfminer.layout import LAParamsfrom io import StringIOfrom io import opendef readPDF(pdfFile): rsrcmgr = PDFResourceManager() retstr = StringIO() laparams = LAParams() device = TextConverter(rsrcmgr, retstr, laparams=laparams) process_pdf(rsrcmgr, device, pdfFile) device.close() content = retstr.getvalue() retstr.close() return contentpdfFile = urlopen("http://pythonscraping.com/pages/warandpeace/chapter1.pdf")#远程outputString = readPDF(pdfFile)print(outputString)pdfFile.close()
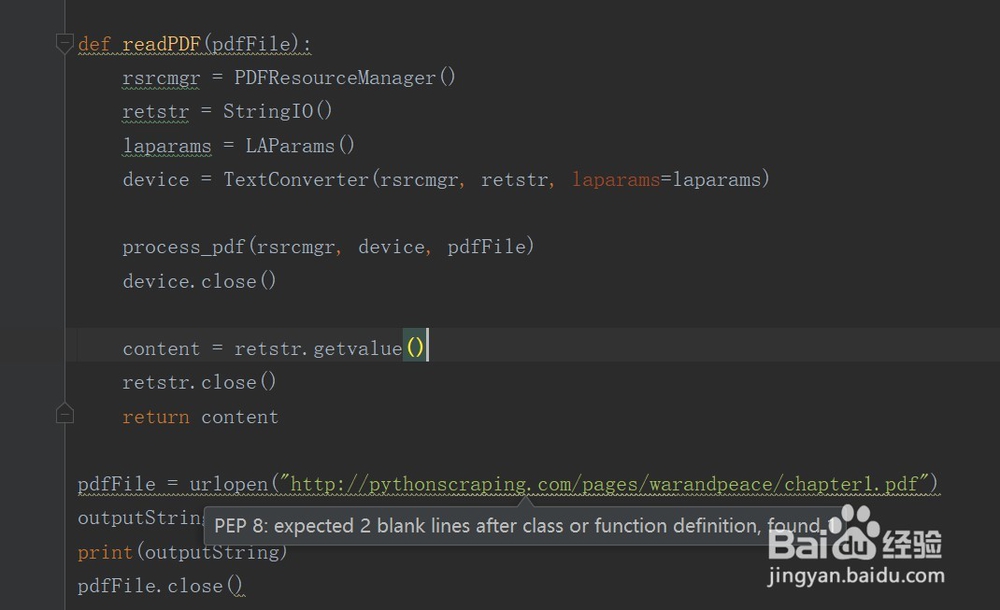
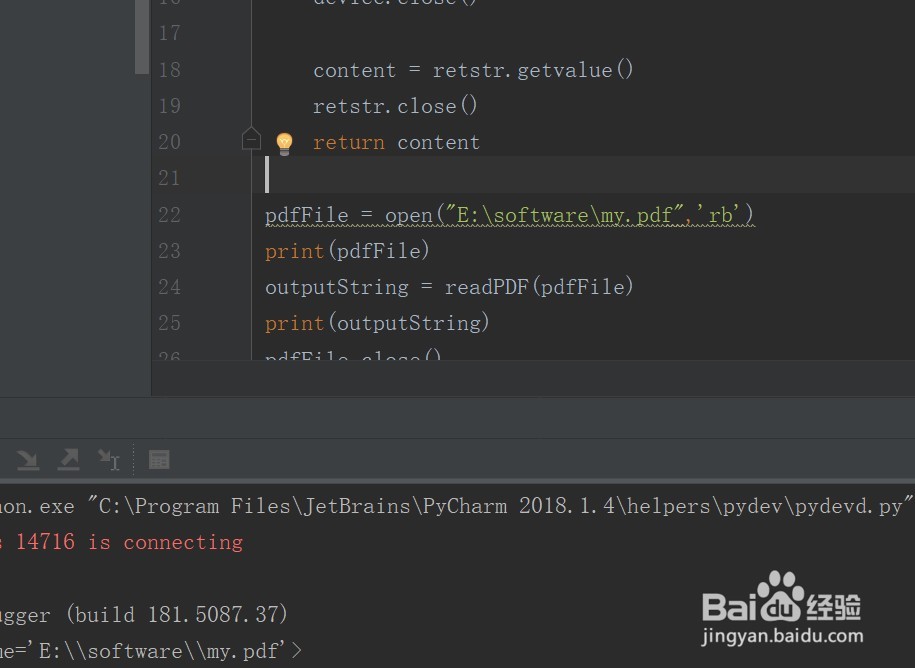
4、读取一个本地pdf文件,输出字符串
# -*- coding: UTF-8 -*from urllib import urlopenfrom pdfminer.pdfinterp import PDFResourceManager, process_pdffrom pdfminer.converter import TextConverterfrom pdfminer.layout import LAParamsfrom io import StringIOfrom io import opendef readPDF(pdfFile): rsrcmgr = PDFResourceManager() retstr = StringIO() laparams = LAParams() device = TextConverter(rsrcmgr, retstr, laparams=laparams) process_pdf(rsrcmgr, device, pdfFile) device.close() content = retstr.getvalue() retstr.close() return contentpdfFile = open(u"轿召爬/home/mypdf.pdf",”rd”特彩) #本地
print(pdfFile)outputString = readPDF(pdfFile)print(outputString)pdfFile.close()