php制作简单的采集代码
1、首先在页面加入一个文本框和提交按钮,文本框用来输入采集页面地址。

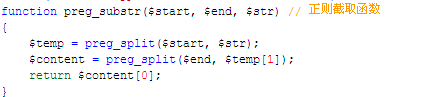
2、采集需要用到正则截取函数
function preg_substr($start, $end, $str) // 正则截取函数
{
$temp = preg_split($start, $str);
$content = preg_split($end, $temp[1]);
return $content[0];
}
3、采集需要用到字符串截取函数
function str_substr($start, $end, $str) // 字符串截取函数
{
$temp = explode($start, $str, 2);
$content = explode($end, $temp[1], 2);
return $content[0];
}

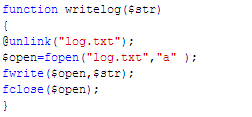
4、还有一个保存采集的内容的函数:
function writelog($str)
{
@unlink("log.txt");
$open=fopen("log.txt","a" );
fwrite($open,$str);
fclose($open);
}
有时候采集到的内容和我们通过浏览器查看的内容不一致,导致我们找不到正确的正则表达式,这里就可以打开保存的txt文件,在里面找到正确的截取字符串。
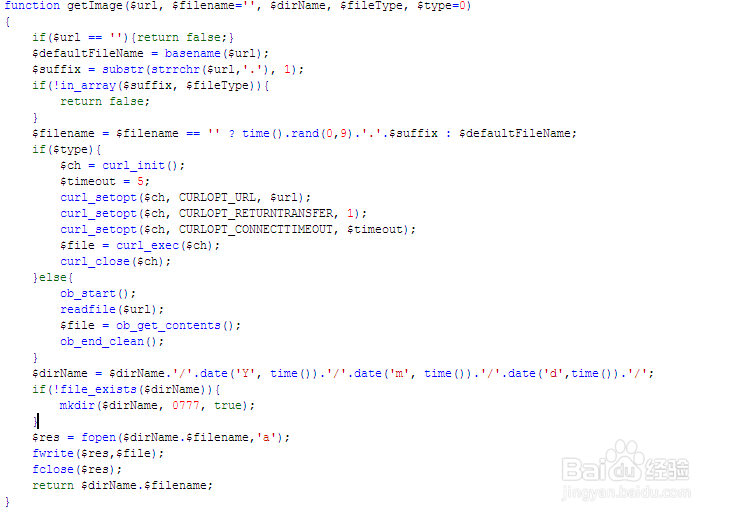
5、如果需要连图片也采集下来就需要用到图片函数:
function getImage($url, $filename='', $dirName, $fileType, $type=0)
{
if($url == ''){return false;}
//获取文件原文件名
$defaultFileName = basename($url);
//获取文件类型
$suffix = substr(strrchr($url,'.'), 1);
if(!in_array($suffix, $fileType)){
return false;
}
//设置保存后的文件名
$filename = $filename == '' ? time().rand(0,9).'.'.$suffix : $defaultFileName;
//获取远程文件资源
if($type){
$ch = curl_init();
$timeout = 5;
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, $timeout);
$file = curl_exec($ch);
curl_close($ch);
}else{
ob_start();
readfile($url);
$file = ob_get_contents();
ob_end_clean();
}
//设置文件保存路径
$dirName = $dirName.'/'.date('Y', time()).'/'.date('m', time()).'/'.date('d',time()).'/';
if(!file_exists($dirName)){
mkdir($dirName, 0777, true);
}
//保存文件
$res = fopen($dirName.$filename,'a');
fwrite($res,$file);
fclose($res);
return $dirName.$filename;
}
6、加入采集代码,由于这里加入采集代码不让提交,直接上图;
我们以亚马逊的一个产品页为例:输入某个产品链接:


7、看看采集结果如下图,这里只展示内容,加入数据库就比较简单了,有时间再介绍自动进入下级链接或自动翻页的采集。
