实例讲解Python进程池apply_async和apply的区别
1、启动Ubuntu虚拟机,在桌面空白处右键 -- 打开终端。

2、打开终端后,在终端输入命令:
gedit apply.py
创建一个apply.py文件,并在gedit中打开
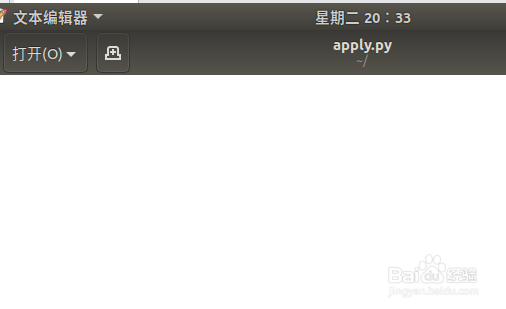
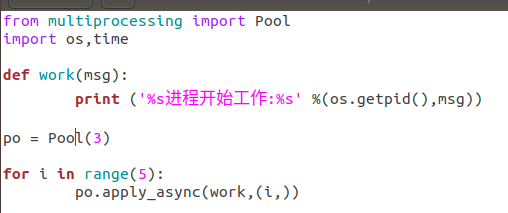
3、在apply.py文件中写代码如下:
from multiprocessing import Pool
import os,time
def work(msg):
print ('%s进程开始工作:%s' %(os.getpid(),msg))
po = Pooll(3)
for i in range(5):
po.apply_async(work,(i,))
这是使用apply_async执行调用函数的方式。
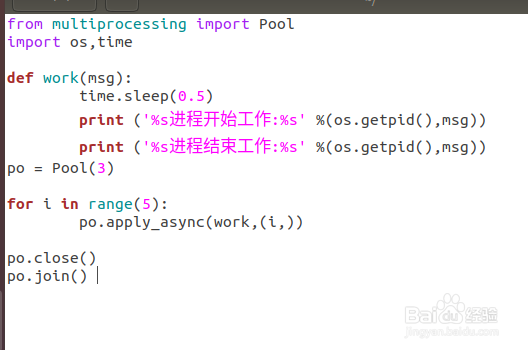
4、继续编写代码,代码如下:
from multiprocessing import Pool
import os,time
def work(msg):
time.sleep(0.5)
print ('%s进程开始工作:%s' %(os.getpid(),msg))
print ('%s进程结束工作:%s' %(os.getpid(),msg))
po = Pool(3)
for i in range(5):
po.apply_async(work,(i,))
po.close()
po.join()
注意没有最后这两行的话,程序运行会直接结束,主进程不会等待子进程的结束。
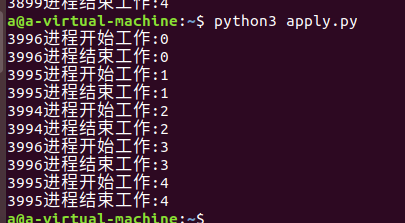
5、保存代码,在终端运行代码,使用命令:
python3 apply.py

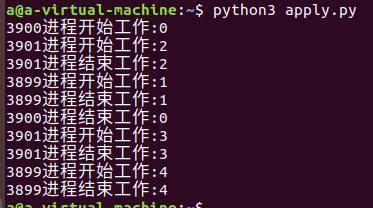
6、回车后,代码运行效果如下图所示,由于在子进程中设置了sleep5秒,所以进程池创建的3子进程,执行先后顺序不一,这是apply_async异步执行的特点。
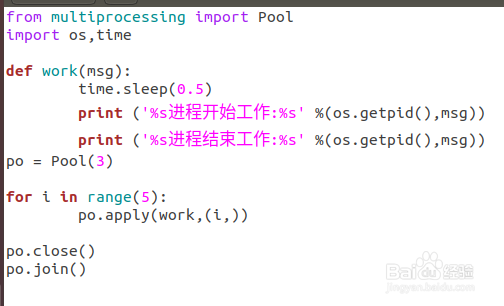
7、修改代码,使用apply函数,代码如下:
from multiprocessing import Pool
import os,time
def work(msg):
time.sleep(0.5)
print ('%s进程开始工作:%s' %(os.getpid(),msg))
print ('%s进程结束工作:%s' %(os.getpid(),msg))
po = Pool(3)
for i in range(5):
po.apply(work,(i,))
po.close()
po.join()
8、保存代码,在终端运行代码
python3 apply.py
代码执行效果如下图,子进程执行的顺序是for循环的顺序,这是因为apply函数每次会等待子进程结束,才执行主进程的for循环操作。