python中如何对csv数据的格式进行处理
1、首先,我们需要下载一个CSV文件,我这里就在网上下载了一个,然后放在了项目文件夹下,防止要写绝对路径的问题。
下面为文件夹目录及CSV文件内容


2、然后代码部分为如下:(注意缩减)
import csv
filename= 'Python-death_valley_2015.csv'
with open(filename) as f:
reader = csv.reader(f)
header_row = next(reader)
heads = []
#遍历文件对象
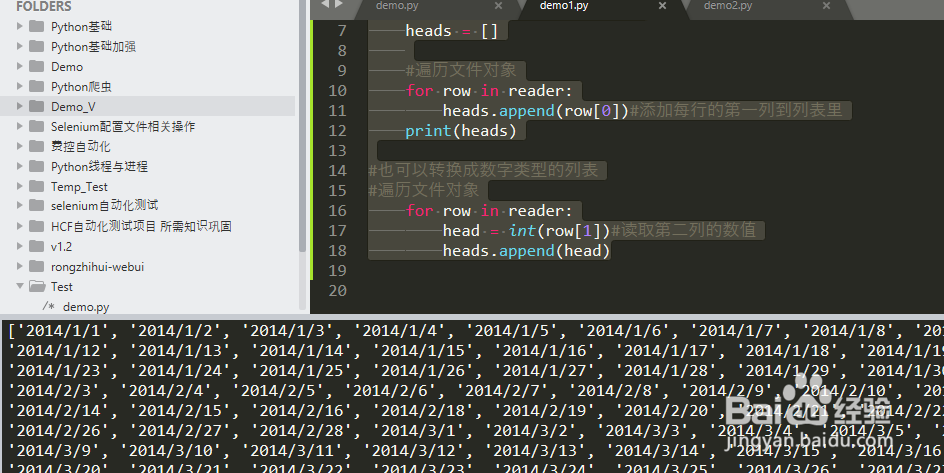
for row in reader:
heads.append(row[0])#添加每行的第一列到列表里
print(heads)
#也可以转换成数字类型的列表
#遍历文件对象
for row in reader:
head = int(row[1])#读取第二列的数值
heads.append(head)

3、下面解释一下主要的方法:
with open(filename) as f 就是Python中文件读写的格式,
然后使用 csv.reader来读取csv文件,
最后就是能读取每行第一列的数据。
1、而使用pandas就比较简单一点,读取的时候也简单一点
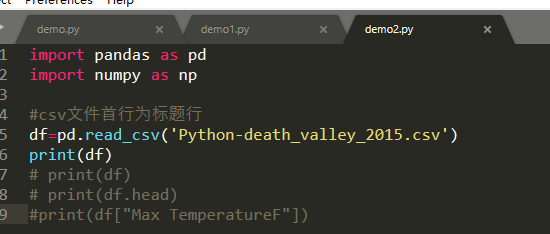
2、代码如下:(注意缩减)
import pandas as pd
import numpy as np
#csv文件首行为标题行
df=pd.read_csv('Python-death_valley_2015.csv')
print(df)
# print(df)
# print(df.head)
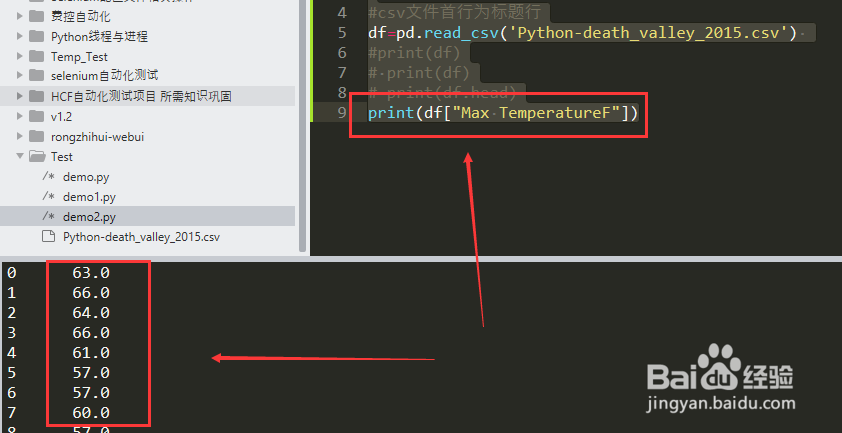
#print(df["Max TemperatureF"])

3、直接输出df对象就是输出csv文件的内容。
然后最后的print(df["Max TemperatureF"])就是输出列名为Max TemperatureF的所有数据