Python中K-邻近算法及分类器建立
1、工作原理:
(1)存在一个样本数据集合(训练样本集),样本集中每个数据都存在标签(每一数据与所属分类的对应关系)。
(2)输入没有标签的新数据
(3)将新数据的每个特征与样本集中数据对应的特征进行比较,然后判断新数据属于哪一类。
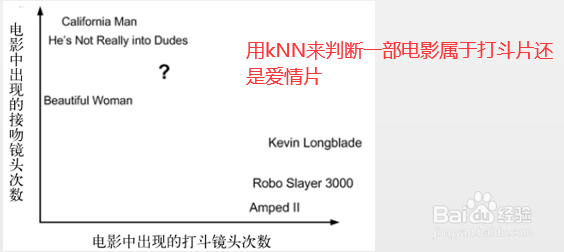
2、案例:电影分类
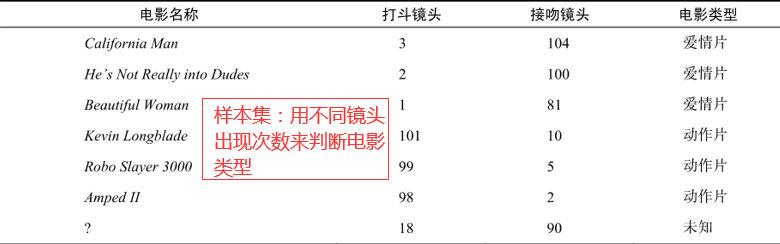
(1)样本集:通过已有的电影,出现打斗或者接吻的镜头,判断电影类型。
(2)测试集:k-近邻算法按照距离最近的三部电影的类型,决定未知电影的类型.

3、KNN算法分类器使用流程为:
收集数据-->准备数据-->分析数据-->训练算法-->测试算法-->使用算法
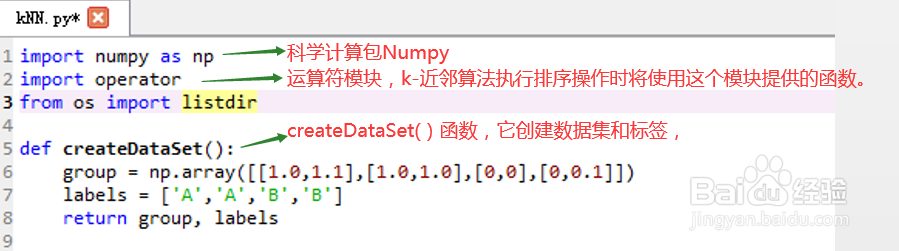
(1)编写KNN.py文件(分类器),其中包括
1)createDataSet()模块:用于产生测试样本集
2)classfy0()模块:用于输入测试数据,判断其分类。
(2)进入python环境,将kNN.py导入
1)使用python导入数据
2)进入E:盘,新建一个文件夹python_example
3)在此文件夹下,创建一个kNN.py的python模块,在kNN.py文件下加入如下代码,保存kNN.py文件。
4)开始/所有程序/Anaconda/anaconda Prompt,打开Python开发环境。
5)cd E:/python_example
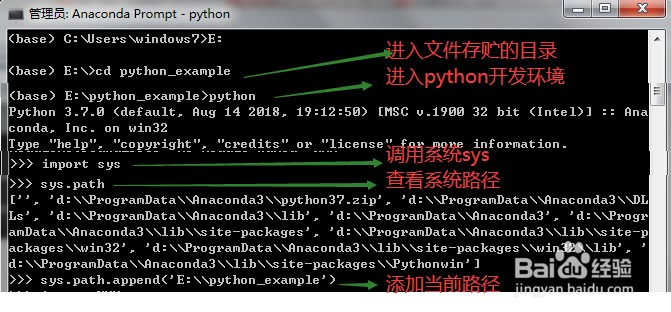
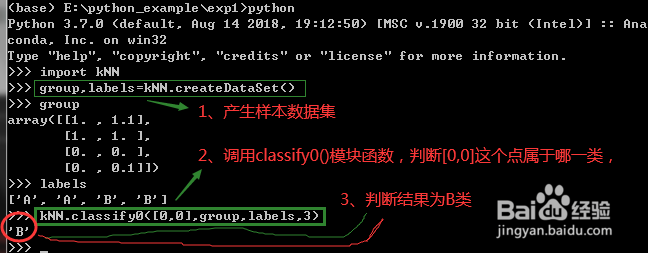
4、(3)使用kNN.py产生样本集
6)改变当前路径到存储kNN.py文件的位置,打开Python开发环境。进入Python开发环境之后,输入下列命令
>>>import sys
>>>sys.path #查看当前变量
>>>sys.path.append('E:\anconda_example')
>>> import kNN #导入kNN模块。
>>> group, labels = kNN.createDataSet()
kNN模块中定义了函数createDataSet,上述命令创建了变量group和1abels
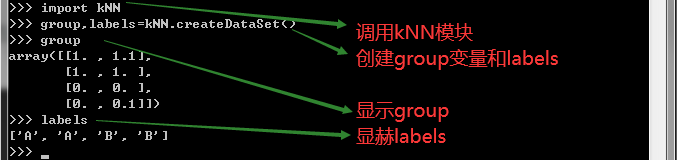
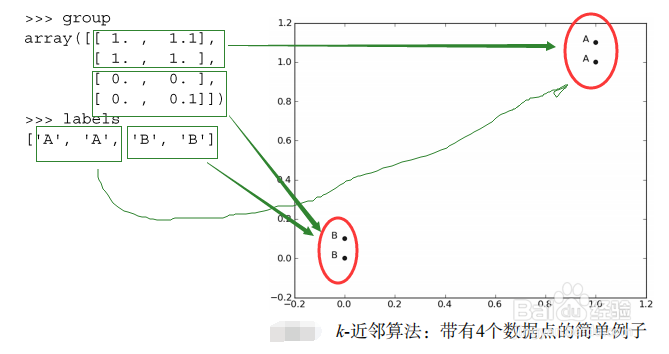
5、(4)分析数据:group,labels对应于不同的类(A类B类)
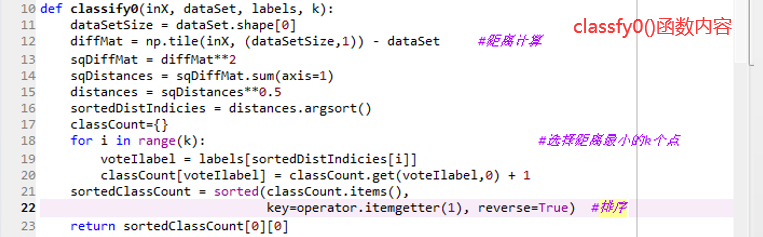
6、(5)k-近邻算法分类器设计原理
主要体现在classfy0()函数上,主要过程为:
1)计算未知点与已知类别数据集中的点的距离;
2)按照距离递增次序排序;
3)选取与当前点距离最小的k个点;
4)确定前k个点所在类别的出现频率;
5)返回前k个点出现频率最高的类别作为当前点的预测分类。
7、分类器的测试
classify0()函数有4个输入参数:
1)用于分类的输入向量是inX
2)输入的训练样本集为dataSet
3)标签向量labels
4)最后的参数k表示用于选择最近邻居的数目
可以采用以下命令,测试分类器是否正常
>>>kNN.classify0([0,0], group, labels, 3)