SQL Server数据库中如何查询重复数据并处理?
1、数据准备:生成重复数据
SELECT name,object_id,type,type_desc,create_date,is_ms_shipped into temp_test FROM sys.objects
insert into temp_test
SELECT top 30 name,object_id,type,type_desc,create_date,is_ms_shipped FROM sys.objects

2、验证是否有重复数据方法一:
select name,object_id,type,type_desc,create_date,is_ms_shipped,count(*) from temp_test
group by name,object_id,type,type_desc,create_date,is_ms_shipped having count(*) >1

3、验证是否有重复数据方法二:
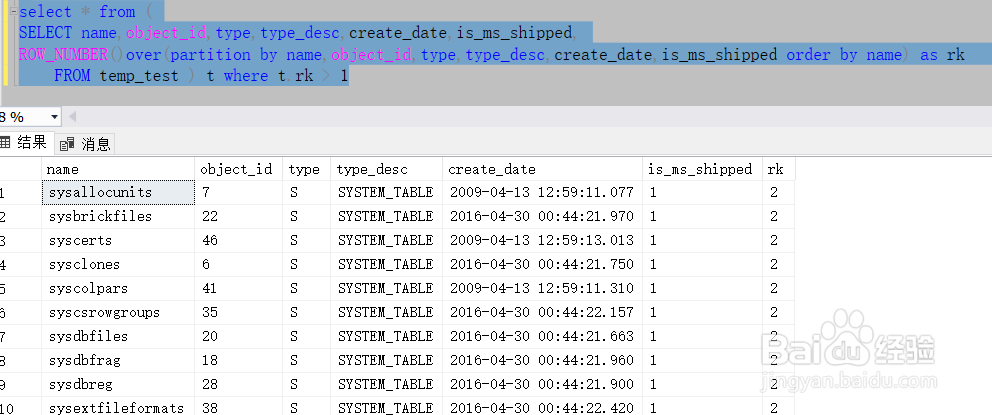
select * from (
SELECT name,object_id,type,type_desc,create_date,is_ms_shipped,
ROW_NUMBER()over(partition by name,object_id,type,type_desc,create_date,is_ms_shipped order by name) as rk
FROM temp_test ) t where t.rk > 1
4、删除重复数据方法一:创建临时表
-- 取去重的数据到备份表
select distinct name,object_id,type,type_desc,create_date,is_ms_shipped into temp_test_new from temp_test
-- 删除重复数据表
drop table if exists temp_test
-- 修改备份表名为原来表名
EXEC sp_rename 'temp_test_new', 'temp_test'

5、删除重复数据方法二:使用“with 子句 和 ROW_NUMBER()函数”来实现删除完全重复的其他行
WITH tab AS(
SELECT ROW_NUMBER()over(partition by object_id order by object_id) as rk
FROM temp_test
)DELETE FROM tab WHERE rk>1

1、要明确通过哪些维度来定位数据时重复的;
2、要学会查找重复数据方法;
3、要学会删除重复数据的方法。