mysql表如何统计过滤和删除重复数据
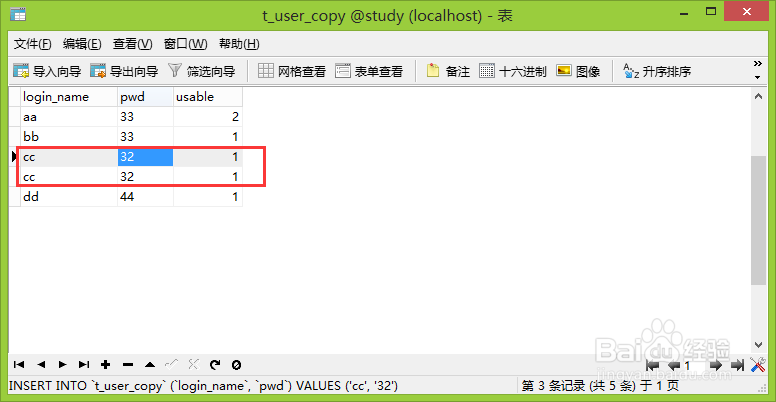
1、首先新建一张表用来演示测试使用,填入几条数据,故意将两条数据填成重复的,为了后面测试效果使用
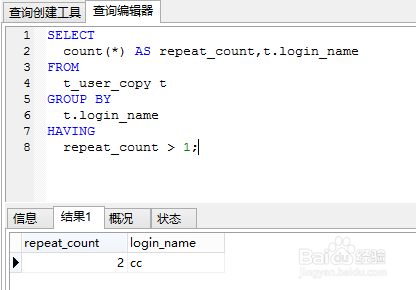
2、统计重复数据
SELECT
count(*) AS repeat_count,t.login_name
FROM
t_user_copy t
GROUP BY
t.login_name
HAVING
repeat_count > 1;
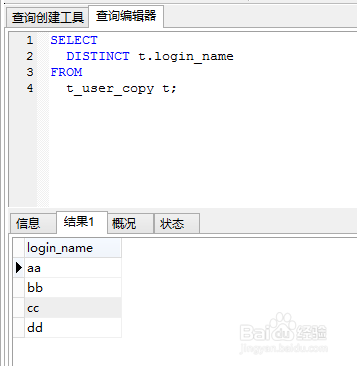
3、使用DISTINCT关键字过滤重复数据
SELECT
DISTINCT t.login_name
FROM
t_user_copy t;
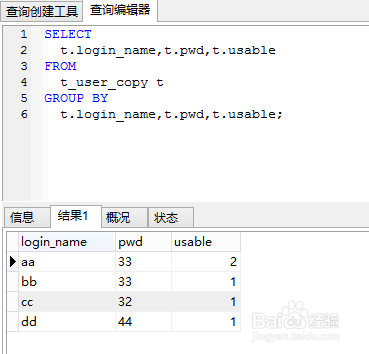
4、还可以使用group by的方式过滤重复的数据
SELECT
t.login_name,t.pwd,t.usable
FROM
t_user_copy t
GROUP BY
t.login_name,t.pwd,t.usable;
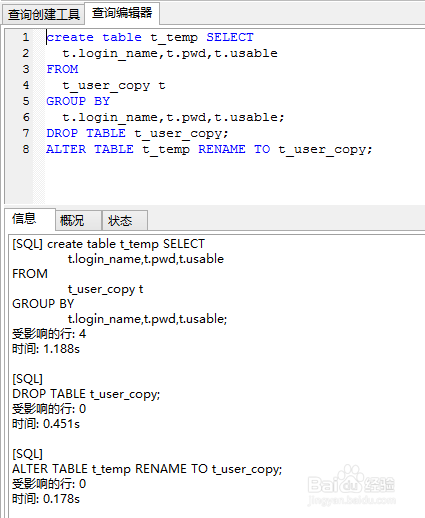
5、删除重复的数据,采用create table select方式从以上过滤完数据的查询结果中创建新表,作为临时表,然后把原来的表drop删除,再把临时表重命名为原来的表名
create table t_temp SELECT
t.login_name,t.pwd,t.usable
FROM
t_user_copy t
GROUP BY
t.login_name,t.pwd,t.usable;
DROP TABLE t_user_copy;
ALTER TABLE t_temp RENAME TO t_user_copy;
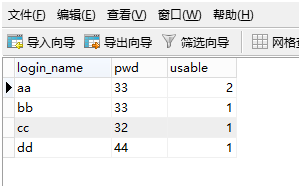
6、再次查询删除之后的表数据,这个时候发现之前的重复数据已经没有了
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:148
阅读量:29
阅读量:177
阅读量:161
阅读量:155