HDFS 的 NameNode工作机制
理解NameNode的工作机制尤其是元数据管理机制,以增强对HDFS工作原理的理解,及培养hadoop集群运营中“性能调优”
“NameNode”故障问题的分析解决能力
1.NameNode职责:
Hadoop集群中有两种节点,一种是NameNode,还有一种是DataNode;其中DataNode主要负责数据的存储,NameNode主
要负责三个功能,分别是;(1)管理元数据 (2)维护目录树 (3)响应客户请求
2.元数据管理:
NameNode对数据的管理采用了三种存储形式:
1.内存元数据(NameSystem)
2.磁盘元数据镜像文件(fsImage)
3.数据操作日志文件(可通过日志运算出元数据)
3.NameNode元数据管理机制
首先介绍下,元数据格式:
%E3%80%82%E5%9C%A8hdfs%E4%B8%AD%EF%BC%8C%E6%96%87%E4%BB%B6%E6%98%AF%E8%BF%9B%E8%A1%8C%E5%88%86%E5%9D%97%E5%AD%98%E5%82%A8%E7%9A%84%EF%BC%8C%E5%A6%82%E6%9E%9C%E6%96%87%E4%BB%B6%E8%BF%87%E5%A4%A7%EF%BC%8C%E5%B0%B1%E8%A6%81%E5%88%86%E6%88%90%E5%A4%9A%E5%9D%97%E5%AD%98%E5%82%A8%EF%BC%8C%E6%AF%8F%E4%B8%AA%E5%9D%97%E5%9C%A8%E6%96%87%E4%BB%B6%E7%B3%BB%E7%BB%9F%E4%B8%AD%E5%AD%98%E5%82%A83%E4%B8%AA%E5%89%AF%E6%9C%AC%EF%BC%8C%E4%BB%A5</p><p>%E4%B8%8A%E5%9B%BE%E4%B8%BA%E4%BE%8B%EF%BC%8C%E5%B0%B1%E6%98%AF%E5%88%86%E6%88%90blk_1%E5%92%8Cblk_2%E4%B8%A4%E4%B8%AA%E5%9D%97%EF%BC%8C%E6%AF%8F%E4%B8%AA%E5%9D%97%E5%9C%A8%E5%AE%9E%E9%99%85%E7%9A%84%E8%8A%82%E7%82%B9%E4%B8%AD%E6%9C%893%E4%B8%AA%E5%89%AF%E6%9C%AC%EF%BC%8C%E6%AF%94%E5%A6%82blk_1%E7%9A%843%E4%B8%AA%E5%89%AF%E6%9C%AC%E5%88%86%E5%88%AB%E5%AD%98%E5%82%A8%E5%9C%A8h0%EF%BC%8Ch1%EF%BC%8Ch3%E4%B8%AD</p><p>%E3%80%80%E3%80%80%E7%8E%B0%E5%9C%A8%E7%94%B1%E6%AD%A4%E5%BC%95%E5%87%BA%E4%B8%80%E4%B8%AA%E9%97%AE%E9%A2%98%EF%BC%8CNamenode%E4%B8%AD%E7%9A%84%E5%85%83%E6%95%B0%E6%8D%AE%E6%98%AF%E5%AD%98%E5%82%A8%E5%9C%A8%E5%93%AA%E9%87%8C%E7%9A%84%EF%BC%9F%E9%A6%96%E5%85%88%EF%BC%8C%E6%88%91%E4%BB%AC%E5%81%87%E8%AE%BE%E5%A6%82%E6%9E%9C%E5%AD%98%E5%82%A8%E5%9C%A8Namenode%E8%8A%82%E7%82%B9%E7%9A%84%E7%A3%81%E7%9B%98%E4%B8%AD%EF%BC%8C%E5%9B%A0%E4%B8%BA%E7%BB%8F</p><p>%E5%B8%B8%E9%9C%80%E8%A6%81%E8%BF%9B%E8%A1%8C%E9%9A%8F%E6%9C%BA%E8%AE%BF%E9%97%AE%EF%BC%8C%E8%BF%98%E6%9C%89%E5%93%8D%E5%BA%94%E5%AE%A2%E6%88%B7%E8%AF%B7%E6%B1%82%EF%BC%8C%E5%BF%85%E7%84%B6%E6%98%AF%E6%95%88%E7%8E%87%E8%BF%87%E4%BD%8E%E3%80%82%E5%9B%A0%E6%AD%A4%EF%BC%8C%E5%85%83%E6%95%B0%E6%8D%AE%E9%9C%80%E8%A6%81%E5%AD%98%E6%94%BE%E5%9C%A8%E5%86%85%E5%AD%98%E4%B8%AD%E3%80%82%E4%BD%86%E5%A6%82%E6%9E%9C%E5%8F%AA%E5%AD%98%E5%9C%A8%E5%86%85%E5%AD%98%E4%B8%AD%EF%BC%8C%E4%B8%80%E6%97%A6%E6%96%AD%E7%82%B9%EF%BC%8C</p><p>%E5%85%83%E6%95%B0%E6%8D%AE%E4%B8%A2%E5%A4%B1%EF%BC%8C%E6%95%B4%E4%B8%AA%E9%9B%86%E7%BE%A4%E5%B0%B1%E6%97%A0%E6%B3%95%E5%B7%A5%E4%BD%9C%E4%BA%86%EF%BC%81%EF%BC%81%EF%BC%81%E5%9B%A0%E6%AD%A4%E5%BF%85%E9%A1%BB%E5%9C%A8%E7%A3%81%E7%9B%98%E4%B8%AD%E6%9C%89%E5%A4%87%E4%BB%BD%EF%BC%8C%E5%9C%A8%E7%A3%81%E7%9B%98%E4%B8%AD%E7%9A%84%E5%A4%87%E4%BB%BD%E5%B0%B1%E6%98%AFfsImage%EF%BC%8C%E5%AD%98%E6%94%BE%E5%9C%A8Namenode%E8%8A%82%E7%82%B9%E5%AF%B9%E5%BA%94%E7%9A%84</p><p>%E7%A3%81%E7%9B%98%E4%B8%AD%E3%80%82%E5%BD%93%E5%9C%A8%E5%86%85%E5%AD%98%E4%B8%AD%E7%9A%84%E5%85%83%E6%95%B0%E6%8D%AE%E6%9B%B4%E6%96%B0%E6%97%B6%EF%BC%8C%E5%A6%82%E6%9E%9C%E5%90%8C%E6%97%B6%E6%9B%B4%E6%96%B0fsImage%E9%95%9C%E5%83%8F%E6%96%87%E4%BB%B6(%E6%96%87%E4%BB%B6%E7%9A%84%E9%9A%8F%E6%9C%BA%E8%AF%BB%E5%86%99)%EF%BC%8C%E4%BC%9A%E5%AF%BC%E8%87%B4%E6%95%88%E7%8E%87%E8%BF%87%E4%BD%8E%EF%BC%8C%E4%BD%86%E5%A6%82%E6%9E%9C%E4%B8%8D%E6%9B%B4%E6%96%B0%EF%BC%8C%E5%B0%B1%E4%BC%9A</p><p>%E5%8F%91%E7%94%9F%E4%B8%80%E8%87%B4%E6%80%A7%E9%97%AE%E9%A2%98%EF%BC%8C%E4%B8%80%E6%97%A6Namenode%E8%8A%82%E7%82%B9%E6%96%AD%E7%94%B5%EF%BC%8C%E5%B0%B1%E4%BC%9A%E4%BA%A7%E7%94%9F%E6%95%B0%E6%8D%AE%E4%B8%A2%E5%A4%B1%E3%80%82%E5%9B%A0%E6%AD%A4%EF%BC%8C%E5%BC%95%E5%85%A5%E6%93%8D%E4%BD%9C%E6%97%A5%E5%BF%97%E6%96%87%E4%BB%B6edits.log(%E5%8F%AA%E8%BF%9B%E8%A1%8C%E8%BF%BD%E5%8A%A0%E6%93%8D%E4%BD%9C%EF%BC%8C%E6%95%88%E7%8E%87%E5%BE%88%E9%AB%98)%E3%80%82</p><p>%E6%AF%8F%E5%BD%93%E5%85%83%E6%95%B0%E6%8D%AE%E6%9C%89%E6%9B%B4%E6%96%B0%E6%88%96%E8%80%85%E6%B7%BB%E5%8A%A0%E5%85%83%E6%95%B0%E6%8D%AE%E6%97%B6%EF%BC%8C%E4%BF%AE%E6%94%B9%E5%86%85%E5%AD%98%E4%B8%AD%E7%9A%84%E5%85%83%E6%95%B0%E6%8D%AE%E5%B9%B6%E8%BF%BD%E5%8A%A0%E5%88%B0edits.log%E4%B8%AD%E3%80%82%E8%BF%99%E6%A0%B7%EF%BC%8C%E4%B8%80%E6%97%A6Namenode%E8%8A%82%E7%82%B9%E6%96%AD%E7%94%B5%EF%BC%8C%E5%8F%AF%E4%BB%A5%E9%80%9A%E8%BF%87%E9%95%9C%E5%83%8F</p><p>%E6%96%87%E4%BB%B6fsImage%E5%92%8Cedits.log%E7%9A%84%E5%90%88%E5%B9%B6%EF%BC%8C%E5%90%88%E6%88%90%E5%85%83%E6%95%B0%E6%8D%AE%E3%80%82%E4%BD%86%E6%98%AF%EF%BC%8C%E5%A6%82%E6%9E%9C%E9%95%BF%E6%97%B6%E9%97%B4%E6%B7%BB%E5%8A%A0%E6%95%B0%E6%8D%AE%E5%88%B0edit.log%E4%B8%AD%EF%BC%8C%E4%BC%9A%E5%AF%BC%E8%87%B4%E8%AF%A5%E6%96%87%E4%BB%B6%E6%95%B0%E6%8D%AE%E8%BF%87%E5%A4%A7%EF%BC%8C%E6%95%88%E7%8E%87%E9%99%8D%E4%BD%8E%E4%B8%94%E4%B8%80</p><p>%E6%97%A6%E6%96%AD%E7%94%B5%EF%BC%8C%E6%81%A2%E5%A4%8D%E5%85%83%E6%95%B0%E6%8D%AE%E9%9C%80%E8%A6%81%E7%9A%84%E6%97%B6%E9%97%B4%E8%BF%87%E9%95%BF%E3%80%82%E5%9B%A0%E6%AD%A4%EF%BC%8C%E9%9C%80%E8%A6%81%E5%AE%9A%E6%9C%9F%E8%BF%9B%E8%A1%8CfsImage%E5%92%8Cedits.log%E7%9A%84%E5%90%88%E5%B9%B6%EF%BC%8C%E5%A6%82%E6%9E%9C%E8%BF%99%E4%B8%AA%E6%93%8D%E4%BD%9C%E7%94%B1Namenode%E8%8A%82%E7%82%B9%E5%AE%8C%E6%88%90%EF%BC%8C%E5%8F%88%E4%BC%9A</p><p>%E6%95%88%E7%8E%87%E8%BF%87%E4%BD%8E%E3%80%82%E5%9B%A0%E6%AD%A4%EF%BC%8C%E5%BC%95%E5%85%A5%E4%B8%80%E4%B8%AA%E6%96%B0%E7%9A%84%E8%8A%82%E7%82%B9secondaryNamenode%EF%BC%8C%E4%B8%93%E9%97%A8%E7%94%A8%E4%BA%8EfsImage%E5%92%8Cedits.log%E7%9A%84%E5%90%88%E5%B9%B6%E3%80%82</p><p>%E5%85%83%E6%95%B0%E6%8D%AE%E7%9A%84Checkpoint%EF%BC%9A%E6%AF%8F%E9%9A%94%E4%B8%80%E6%AE%B5%E6%97%B6%E9%97%B4%EF%BC%8C%E7%94%B1secondaryNamenode%E5%B0%86Namenode%E4%B8%8A%E7%A7%AF%E7%B4%AF%E7%9A%84%E6%89%80%E6%9C%89edits%E5%92%8C%E4%B8%80%E4%B8%AA%E6%9C%80%E6%96%B0%E7%9A%84fsimage%E4%B8%8B%E8%BD%BD%E5%88%B0%E6%9C%AC%E5%9C%B0%EF%BC%8C</p><p>%E5%B9%B6%E5%8A%A0%E8%BD%BD%E5%88%B0%E5%86%85%E5%AD%98%E8%BF%9B%E8%A1%8Cmerge%EF%BC%88%E8%BF%99%E4%B8%AA%E8%BF%87%E7%A8%8B%E7%A7%B0%E4%B8%BAcheckpoint%EF%BC%89</p><p>%E5%85%83%E6%95%B0%E6%8D%AE%E7%9A%84Checkpoint%E5%A4%84%E7%90%86%E8%BF%87%E7%A8%8B%E7%9A%84%E5%85%B7%E4%BD%93%E6%AD%A5%E9%AA%A4%E5%A6%82%E4%B8%8B:</p><p>%E3%80%80%E3%80%80%E3%80%80%E3%80%801)Namenode%E8%8A%82%E7%82%B9%E6%AF%8F%E9%9A%94%E4%B8%80%E5%AE%9A%E6%97%B6%E9%97%B4%E8%AF%B7%E6%B1%82secondaryNamenode%E5%90%88%E5%B9%B6%E6%93%8D%E4%BD%9C(%E6%BB%A1%E8%B6%B3%E8%A7%A6%E5%8F%91%E6%9D%A1%E4%BB%B6)</p><p>2)secondaryNamenode%E8%AF%B7%E6%B1%82Namenode%E8%BF%9B%E8%A1%8Cedits.log%E7%9A%84%E6%BB%9A%E5%8A%A8%EF%BC%8C%E8%BF%99%E6%A0%B7%E6%96%B0%E7%9A%84%E7%BC%96%E8%BE%91%E6%93%8D%E4%BD%9C%E5%B0%B1%E8%83%BD%E5%A4%9F%E8%BF%9B%E5%85%A5%E6%96%B0%E7%9A%84%E6%96%87%E4%BB%B6%E4%B8%AD</p><p>%E3%80%80%E3%80%80%E3%80%80%E3%80%803)secondaryNamenode%E4%BB%8Enamenode%E4%B8%AD%E4%B8%8B%E8%BD%BDfsImage%E5%92%8Cedits.log</p><p>%E3%80%80%E3%80%80%E3%80%80%E3%80%804)secondaryNamenode%E8%BF%9B%E8%A1%8CfsImage%E5%92%8Cedits.log%E7%9A%84%E5%90%88%E5%B9%B6,%E6%88%90%E4%B8%BAfsImage.checkpoint%E6%96%87%E4%BB%B6</p><p>%E3%80%80%E3%80%80%E3%80%80%E3%80%805)namenode%E4%B8%8B%E8%BD%BD%E5%90%88%E5%B9%B6%E5%90%8E%E7%9A%84fsImage.checkpoin%E6%96%87%E4%BB%B6</p><p>%E3%80%80%E3%80%80%E3%80%80%E3%80%806)%E5%B0%86fsImage.checkpoint%E5%92%8Cedits.new%E5%91%BD%E5%90%8D%E4%B8%BA%E5%8E%9F%E6%9D%A5%E7%9A%84%E6%96%87%E4%BB%B6%E5%90%8D(%E8%BF%99%E6%A0%B7%E4%B9%8B%E5%90%8EfsImage%E5%92%8C%E5%86%85%E5%AD%98%E4%B8%AD%E7%9A%84%E5%85%83%E6%95%B0%E6%8D%AE%E5%8F%AA%E5%B7%AEedits.new</p><p>%E5%85%83%E6%95%B0%E6%8D%AE%E7%9A%84Checkpoint%E6%9C%BA%E5%88%B6%E6%B5%81%E7%A8%8B%E5%9B%BE%EF%BC%9A</p><p><img%20src=)
4.CheckPoint操作的触发条件配置参数
dfs.namenode.checkpoint.check.period=60#检查触发条件是否满足的频率,60秒
dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary#以上两个参数做checkpoint操作时,secondary namenode的本地工作目录
dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir}
dfs.namenode.checkpoint.max-retries=3#最大重试次数
dfs.namenode.checkpoint.period=3600#两次checkpoint之间的时间间隔3600秒
dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录
5.总结:
5.1.元数据存储机制
A、内存中有一份完整的元数据(内存metadata)
B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
C、用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)
注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据
会更新到内存metadata中
5.2.如果NameNode的硬盘损坏,元数据是否还能恢复,如果能恢复,该如何恢复?
:可恢复绝大部分数据,NameNode和secondaryNamenode的工作目录存储结构完全相同,所以,当Namenode故障退出需要重新恢复时,
可以将SecondaryNamenode的工作目录拷贝到namenode的工作目录,以恢复namenode的元数据

5.3.如果NameNode宕机,hdfs服务能否正常提供?
:不能,虽然SecondaryNamenode有元数据信息,但不能更新元数据,不能充当NameNode使用;
5.4.通过以上思考,我们在配置NameNode工作目录参数时,应该注意什么?
:NameNode的工作目录应该配置在多块磁盘上,同时往多块磁盘上写日志,数据时相同的;
:修改NameNode的配置文件:vi /usr/local/src/hadoop-2.6.4/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.name.dir</name>
<value>/disk1/name1,/disk2/name2</value>
</property>
:然后重新对NameNode format :hadoop namenode -format,会重新生成两个name1和name2目录
:dfs.name.dir属性可以配置多个目录,各个目录存储的文件结构和内容完全相同,相当于备份,这样做的好处就是当其中
一个目录损坏了,也不会影响到Hadoop的元数据,
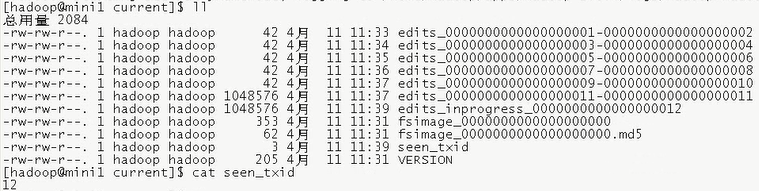
5.5.补充:该hdpdata/dfs/name/current/目录下的seen_txid文件:
:该文件中记录的是edits滚动的序号,每次重启NnmeNode时,NnmeNode就知道该加载哪些edits(序号小的)