Python提取列的不重复数据
1、导入包
import pandas as pd
2、获取示例文件,提取数据
df = pd.read_excel(r"C:\Users\zhang\Desktop\合并0929.xlsx",sheet_name="合并")
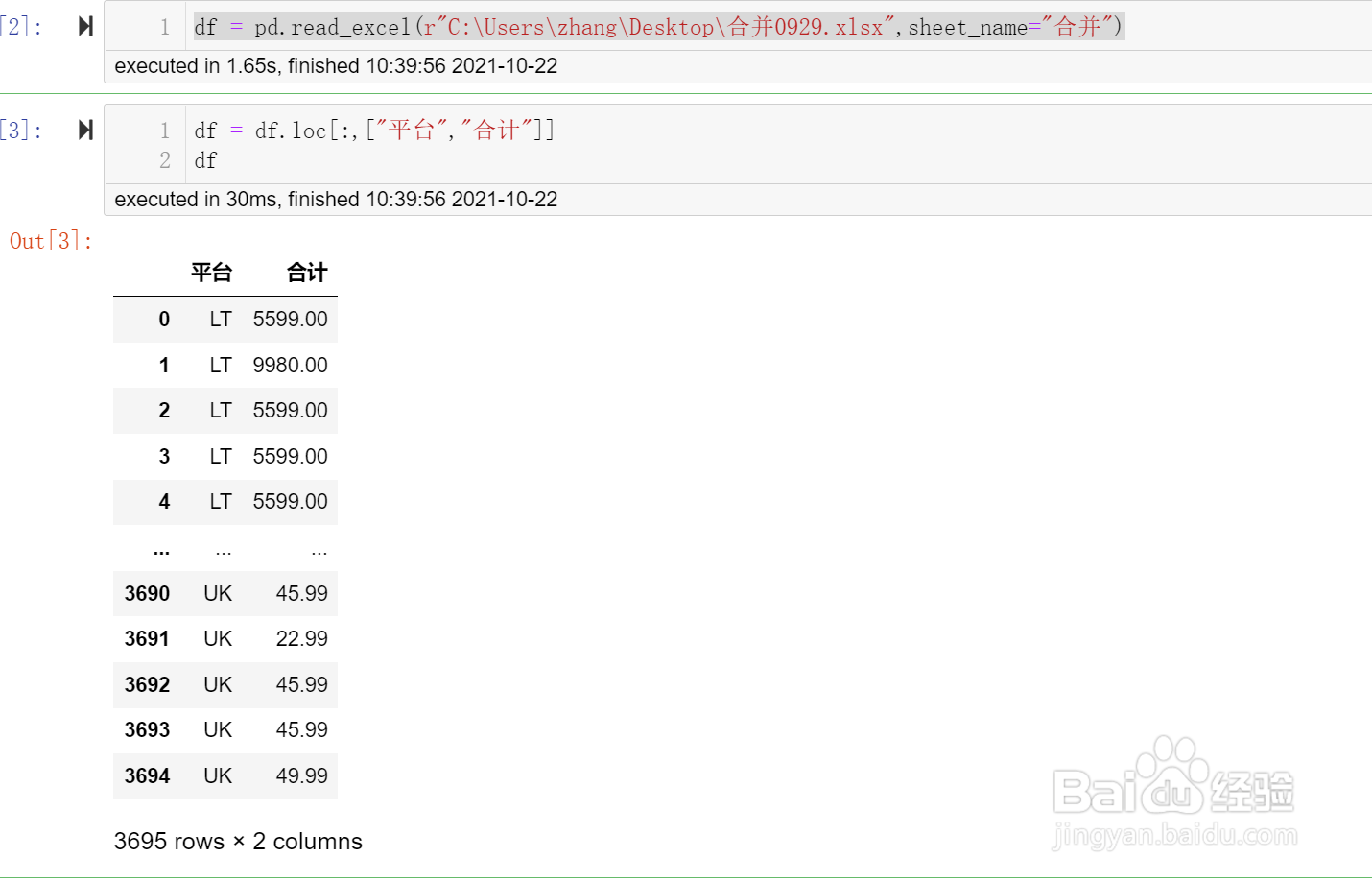
df = df.loc[:,["平台","合计"]]
print(df)
获取的数据共有3695行
3、提取列数据转换成列表
a = df["平台"].tolist()
len(a)
列表长度为3695

4、将列表转换成集合
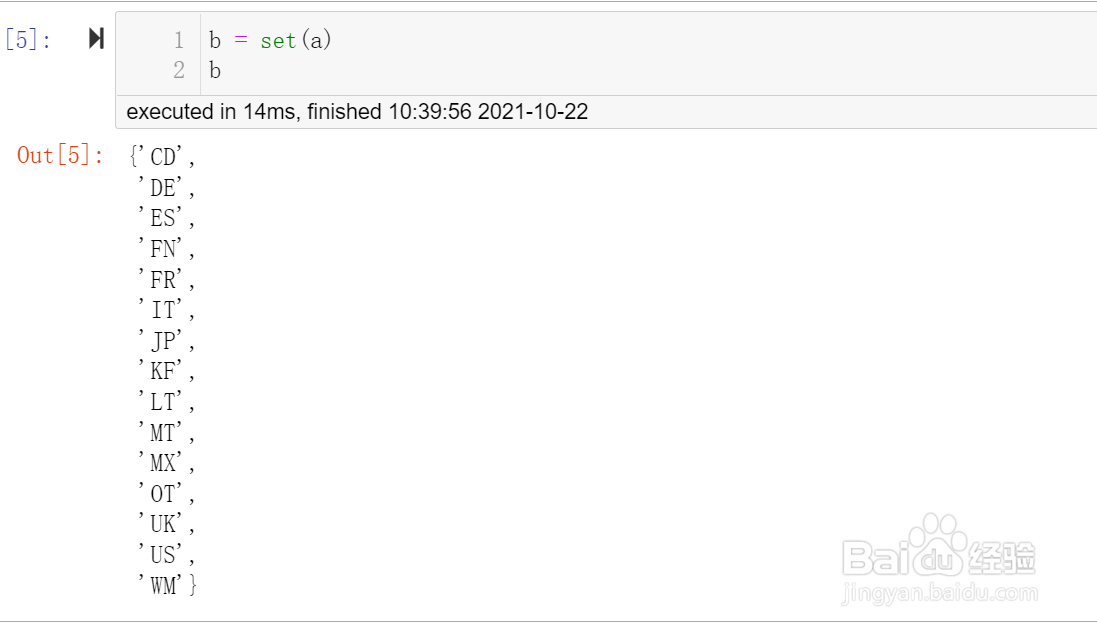
b = set(a)
去重后数据长度为15
集合内是不能存在重复值,达到了去重的目的
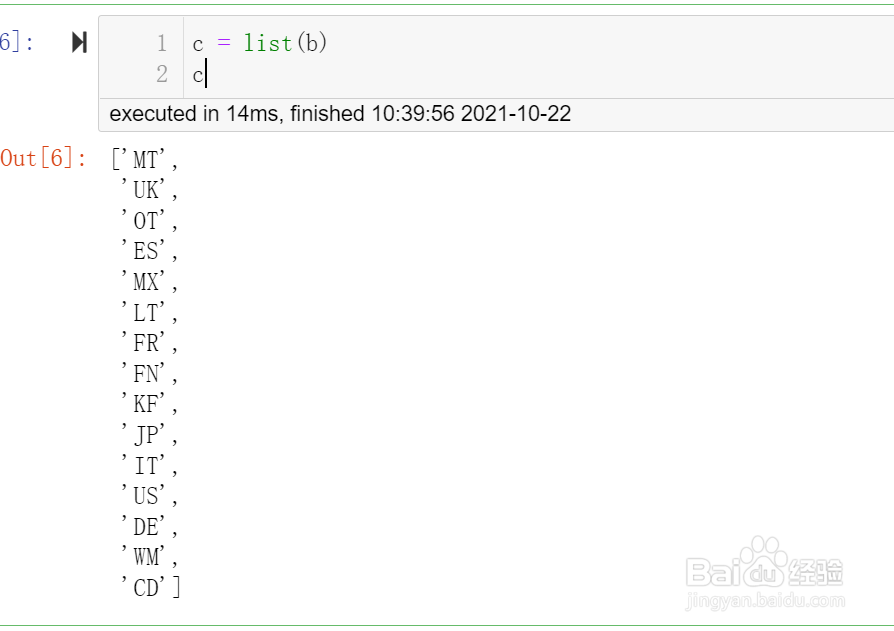
5、最后将集合转换成列表
c = list(b)
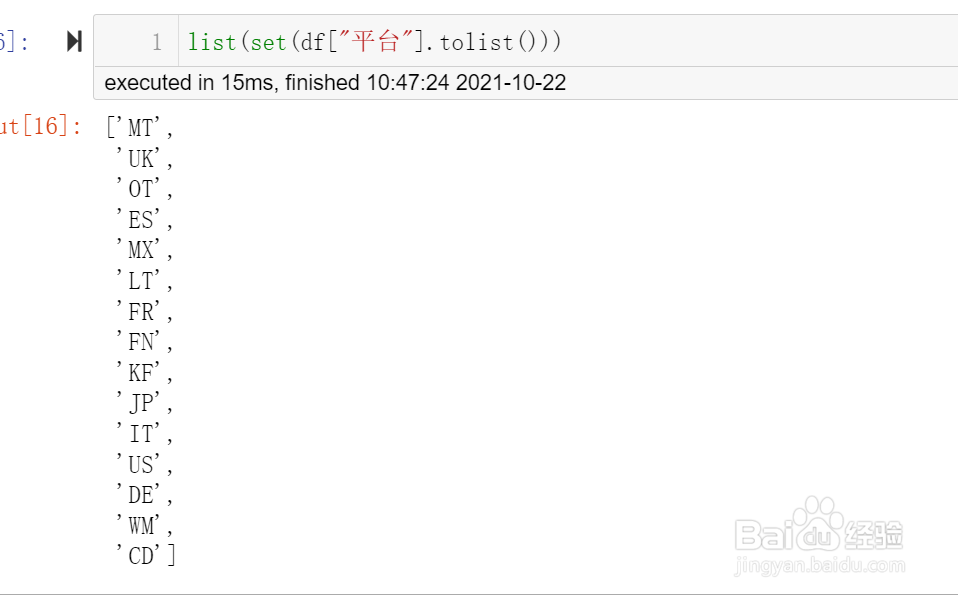
6、这几条可以写在一行里
list(set(df["平台"].tolist()))
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:166
阅读量:37
阅读量:67
阅读量:125
阅读量:120