python爬取贴吧内容实例
1、打开python开发工具IDLE,新建‘tieba.py’文件,并写代码如下:
import urllib.request
import bs4
导入urllib请求包和beautifulsoup处理包

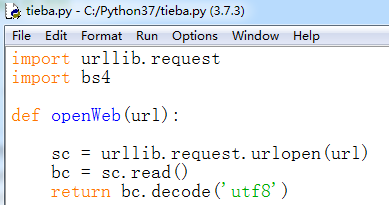
2、创建发送请求的函数,函数返回网页源码,代码如下:
def openWeb(url):
sc = urllib.request.urlopen(url)
bc = sc.read()
return bc.decode('utf8')
3、打开python

4、F12打开开发者模式,观察所有title的结构

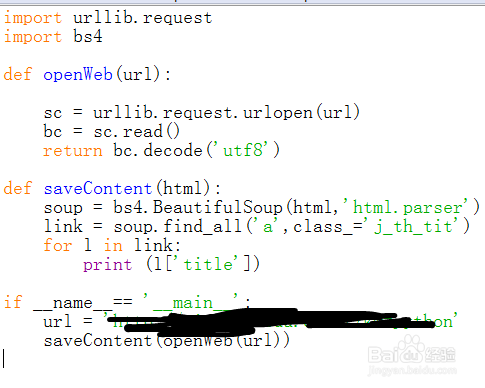
5、编写处理网页源码的函数,代码如下:
def saveContent(html):
soup = bs4.BeautifulSoup(html,'html.parser')
link = soup.find_all('a',class_='j_th_tit')
for l in link:
print (l['title'])

6、编写程序入口函数,调度上面的两个函数,代码如下:
7、F5运行代码,打印出所有title

声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:118
阅读量:62
阅读量:39
阅读量:176
阅读量:93