基于keras和tensorflow的手写数字识别训练
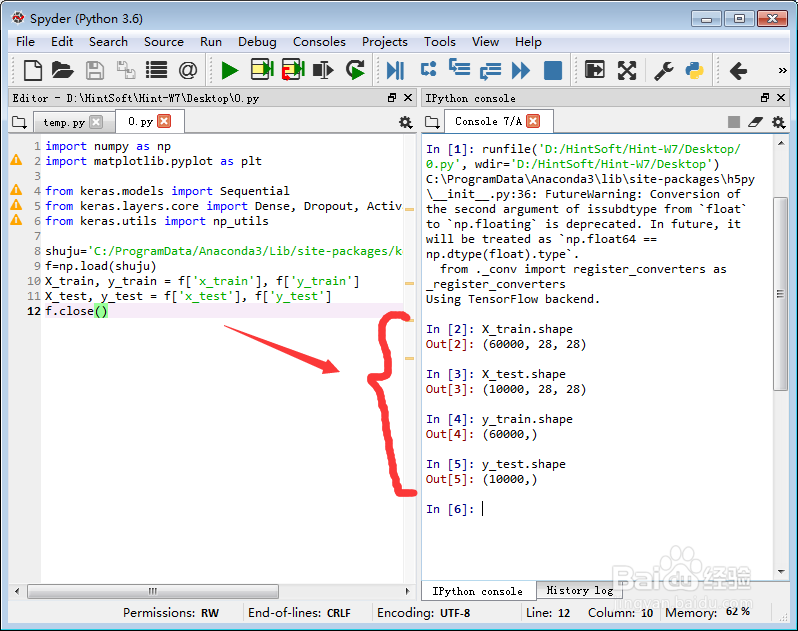
1、把下载下来的资源,放到某个文件夹里面,然后打开python编译器,读取数据:
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.utils import np_utils
shuju='……/mnist.npz' #¥¥¥这里读取资源的绝对路径
f=np.load(shuju)
X_train, y_train = f['x_train'], f['y_train']
X_test, y_test = f['x_test'], f['y_test']
f.close()
读取数据的方式,如上所示,资源本身已经把数据集分成了训练集和测试集;
读完了数据,就要关闭读取的过程,节省内存。
2、修改数据集的样式:
X_train = X_train.reshape(X_train.shape[0], -1)
X_test = X_test.reshape(X_test.shape[0], -1)
X_train = X_train.astype("float32")
X_test = X_test.astype("float32")
X_train /= 255
X_test /= 255
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10)
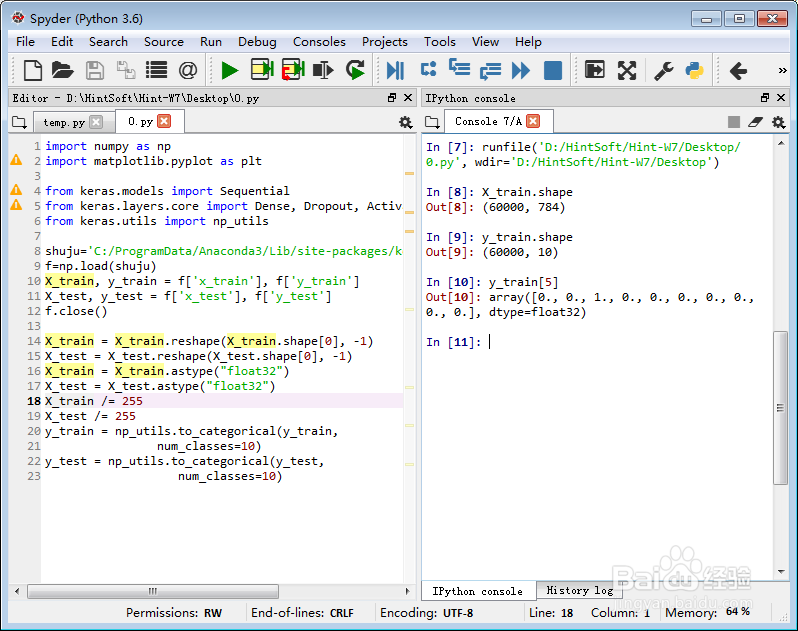
上面,X_train和X_test分别是手写数字的图片的数据,都是28*28大小的灰度图。我们需要把每一幅图片转化为长度为28*28=784的向量;
而y_train和y_test则是手写数字的标签,写的是数字几,标签就是几(从0到9)。我们需要把标签转化为10阶向量里面的元素都是0或1。比如标签为3,就把标签转化为向量(0,0,0,1,0,0,0,0,0)。y_train[5]等于[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],表示对应的数字是2。
3、创建一个序贯模型:
model = Sequential()
model.add(Dense(512, input_shape=(784,)))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.2))
model.add(Dense(10))
model.add(Activation('softmax'))

4、编译模型:
model.compile(loss = 'categorical_crossentropy',
optimizer = 'rmsprop',
metrics=['accuracy'])
度量方法是'accuracy',优化器是'rmsprop',损失函数是'categorical_crossentropy'。

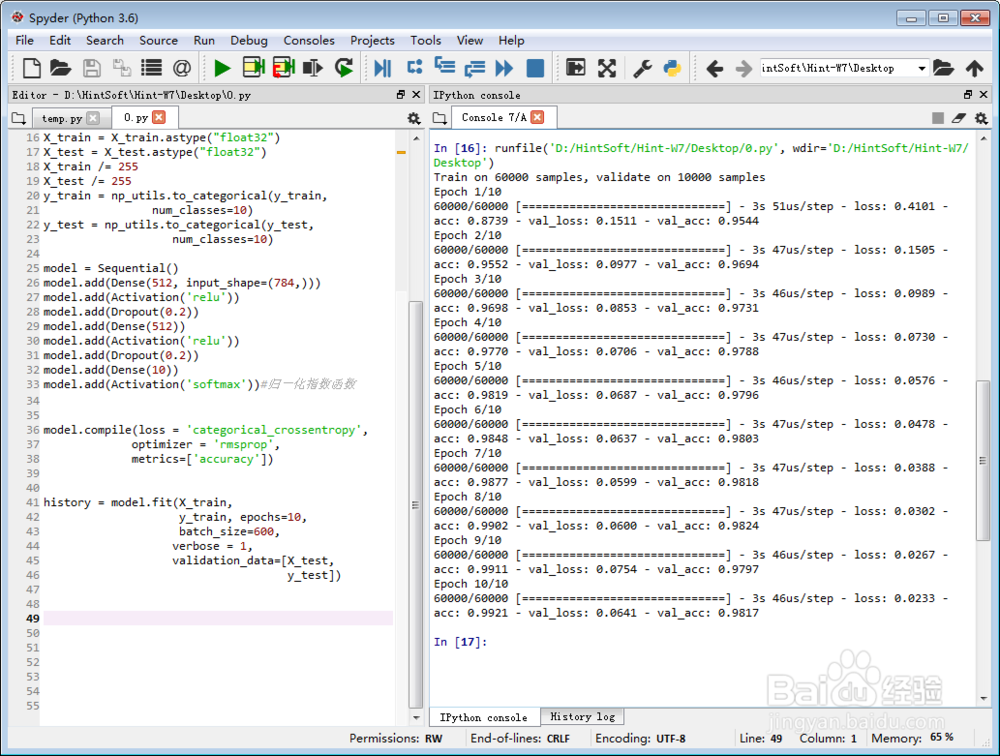
5、开始训练:
history = model.fit(X_train,
y_train, epochs=10,
batch_size=600,
verbose = 1,
validation_data=[X_test,
y_test])
训练的数据是[X_test, y_test];
每一批有600个数据——batch_size=600;
训练10次,也就是优化10次。这10次,把误差从0.15降为了0.6。
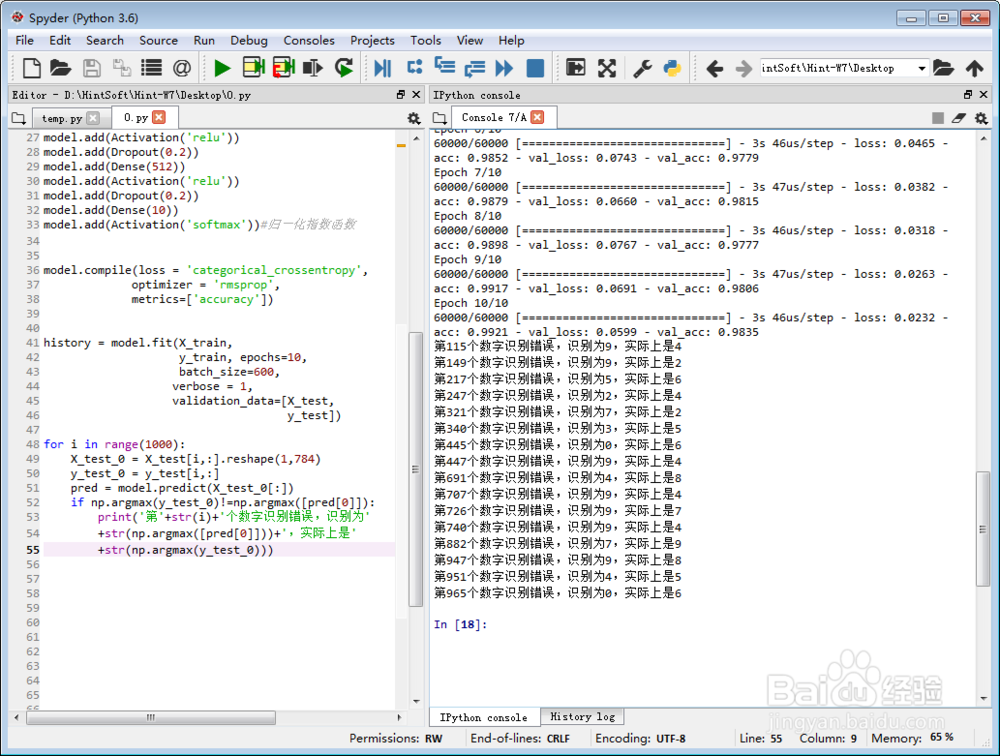
6、检测训练成果:
for i in range(1000):
X_test_0 = X_test[i,:].reshape(1,784)
y_test_0 = y_test[i,:]
pred = model.predict(X_test_0[:])
if np.argmax(y_test_0)!=np.argmax([pred[0]]):
print('第'+str(i)+'个数字识别错误,识别为'
+str(np.argmax([pred[0]]))+',实际上是'
+str(np.argmax(y_test_0)))
我们选择了测试集里面前1000个数据,看看有哪些不能识别。
7、最后,别忘了保存模型。
model.save('数字识别.h5')
读取模型的方法是:
from keras.models import load_model
model = load_model('数字识别.h5')
