搜索引擎的基本工作原理
1、对于搜索引擎来说, 要抓取互联网上所有的网页几乎是不可能的, 从目前公布的数据来
看, 容量最大的搜索引擎也不过是抓取了整个网页数量的百分之四十左右。 一方面原因是抓
取技术存在瓶颈,无法遍历所有网页,有许多网页无法从其它网页的链接中找到;另一个原
因是存储技术和处理技术的问题,如果按照每个页面平均大小 20K 计算(包含图片) ,100
亿网页的容量是 100×2000G 字节,即使能够存储,下载也存在问题(按照一台机器每秒下
载 20K 计算,需要 340 台机器不停的下载一年时间,才能把所有网页下载完毕) 。同时,由
于数据量太大,在提供搜索时也会有效率方面的影响。因此,许多搜索引擎的网络蜘蛛只是
抓取那些重要的网页,而评价重要性的主要依据是某个网页的链接深度。
2、有人会认为搜索引擎在接收到搜索请求时,会实时地从全球所有的服务器上查询信息,
并把查询结果展示在用户面前,这其实是一种误解。如果搜索引擎是这样工作的,那么查询
一条信息可能要等上好几年才能得到搜索结果,这还不包括期间网页发生的变化。
实际上, 搜索引擎会预先去拜访大量的网站, 并把这些网页的部分信息预先存储在自己
的服务器上,这样,当用户搜索的时候,其实是在搜索引擎自己的服务器中进行查询,就像
我们在自己的电脑中查询文件一样。
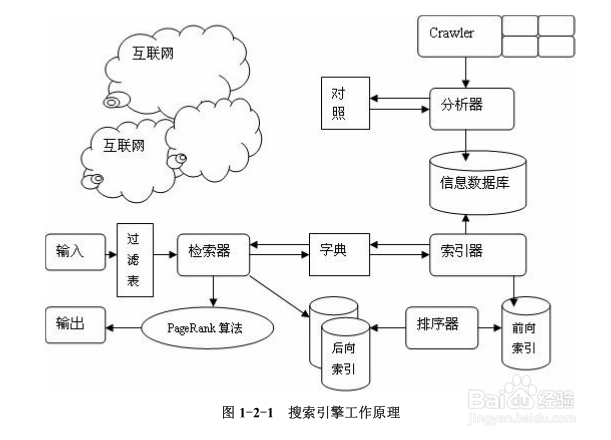
搜索引擎是非常复杂的技术,但是其基本原理并不复杂,其基本技术包括抓取、索引、
排序。
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:125
阅读量:55
阅读量:106
阅读量:43
阅读量:112