“随机森林”分类器的python实现过程
1、需要以下模块:
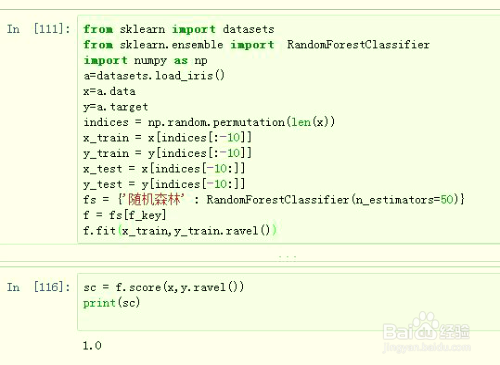
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier
import numpy as np
数据集还是iris:
a=datasets.load_iris()
至于怎么使用这组数据,完全照搬《KNN分类器的实现过程(python)》的方法。

2、创建一个随机森林分类器:
fs = {'随机森林' : RandomForestClassifier(n_estimators=50)}

3、训练模型:
f = fs[f_key]
f.fit(x_train,y_train.ravel())

4、测试模型:
g = f.predict(x_test)

5、用整个数据集做测试,看看准确率:
sc = f.score(x,y.ravel())
声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:170
阅读量:47
阅读量:162
阅读量:85
阅读量:181