网页采集遇到循环下翻下拉框处理方法
1、定位:循环点击下拉框,并选择下一个元素的步骤。
适用情况:网页内存在可以下拉并选择对应元素的下拉框,采集的数据需要进行下拉框内元素的循环选择。
下面为你示范循环下翻下拉框步骤
步骤一:输入网址→保存网址→点击下拉框→点击循环切换下拉列表选项

2、步骤二:点击提取的元素→点击采集该元素的文本

3、步骤三:手动运行规则判断是否正确→保存并启动

4、示例中,下拉框共有8个选项,采集完成后可以看到共采集8条数据,证明循环下拉完成了所有循环下翻下拉操作。
假如我们希望只循环下翻所有元素中的几条,那么该如何操作呢?
下面为你演示如何循环下翻所有元素的一部分:
整体操作如下:
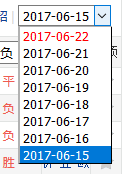

5、重点操作如下:

6、示例中,基本步骤与循环所有元素步骤一致,区别在于循环下拉框的高级设置中,该示例我们希望只循环滚动下拉框中第2到第4个内容,对于还没有学会Xpath的同学,我们可以复制不固定元素列表中的完整XPath,点击固定元素列表,再点击下方内容框,粘贴之前复制的Xpath进去,在后面分别加上你需要的内容顺序,第二条便填写[2],这里需要注意,输入[2]的时候输入法必须处于英文状态下,Xpath只支持英文标点符号的使用。
这里再说明一次循环中高级设置中的各项内容:
操作名为该循环的名字,可以对其进行修改以方便日后对规则的修正;
执行前等待为进行该操作前等待的时间,如果设置执行前等待时间为5秒,则会在翻页完成后等待5秒再循环提取元素,如果希望采集每一个电影的信息前有个等待,则可以在提取步骤设置执行前等待;
或者出现元素是配合执行前等待使用的,在其中输入元素的XPath则可以在出现该元素的时候结束执行前的等待,例如我们设置循环文本步骤执行前等待10秒,或者出现元素设置为电影标题,则翻页操作后,假如第11秒标题加载出来,则采集器会在第10秒尝试进行循环提取操作,而假如第8秒标题加载出来,则采集器会在第8秒标题加载出来后结束循环的执行前等待来尝试进行循环提取操作。
元素在Iframe选项适用于该循环需要采集的内容在网页中是框架,在新手教程中暂不涉及,咱们按下不表。
循环方式包括单个元素、固定元素列表、不固定元素列表、URL列表、以及文本列表。其中单个元素表示只进行一个元素的循环操作,循环点击下一页便多是运用了此种操作;固定元素列表表示循环一些固定的部分,不固定元素列表表示循环一些不固定的部分,在该示例中,如果我们循环采集下拉框中固定位置元素,则是使用固定元素列表,而我们在示例中使用的不固定元素列表则是输入定位的Xpath,该Xpath定位到的所有元素都会出现在循环列表中,例如第一个示例操作;
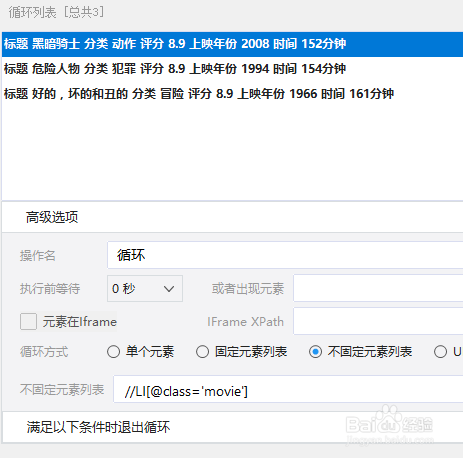
7、URL列表多用于打开多个网页采集内容的时候,可以放入多个网页链接进行循环打开操作;
文本列表则多用于需要输入文字的网页,将列表中多个文本输入网页输入框进行查询。
