C# 提取PDF中的表格
1、鼠标右键点击“引用”,“管理NuGet程序包”,
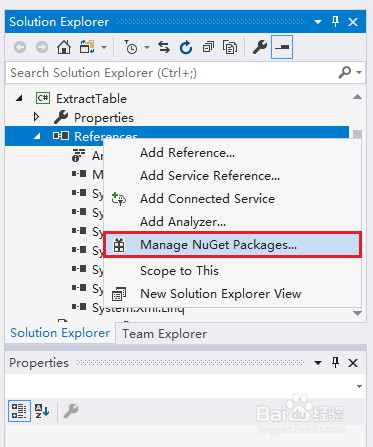
2、点击“浏览”,在搜索框中输入,点击“安装”,

3、或者 使用PM控制台安装:
PM>Install-Package Spire.PDF -Version 7.10.4
1、using Spire.Pdf;
using Spire.Pdf.Utilities;
using System.IO;
using System.Text;
namespace ExtractTable
{
class Program
{
static void Main(string[] args)
{
//加载PDF文档
PdfDocument pdf = new PdfDocument();
pdf.LoadFromFile("sample.pdf");
StringBuilder builder = new StringBuilder();
//抽取表格
PdfTableExtractor extractor = new PdfTableExtractor(pdf);
PdfTable[] tableLists = null;
for (int pageIndex = 0; pageIndex < pdf.Pages.Count; pageIndex++)
{
tableLists = extractor.ExtractTable(pageIndex);
if (tableLists != null && tableLists.Length > 0)
{
foreach (PdfTable table in tableLists)
{
int row = table.GetRowCount();
int column = table.GetColumnCount();
for (int i = 0; i < row; i++)
{
for (int j = 0; j < column; j++)
{
string text = table.GetText(i, j);
builder.Append(text + " ");
}
builder.Append("\r\n");
}
}
}
}
//保存提取的表格内容到txt文档
File.WriteAllText("ExtractedTable.txt", builder.ToString());
}
}
}
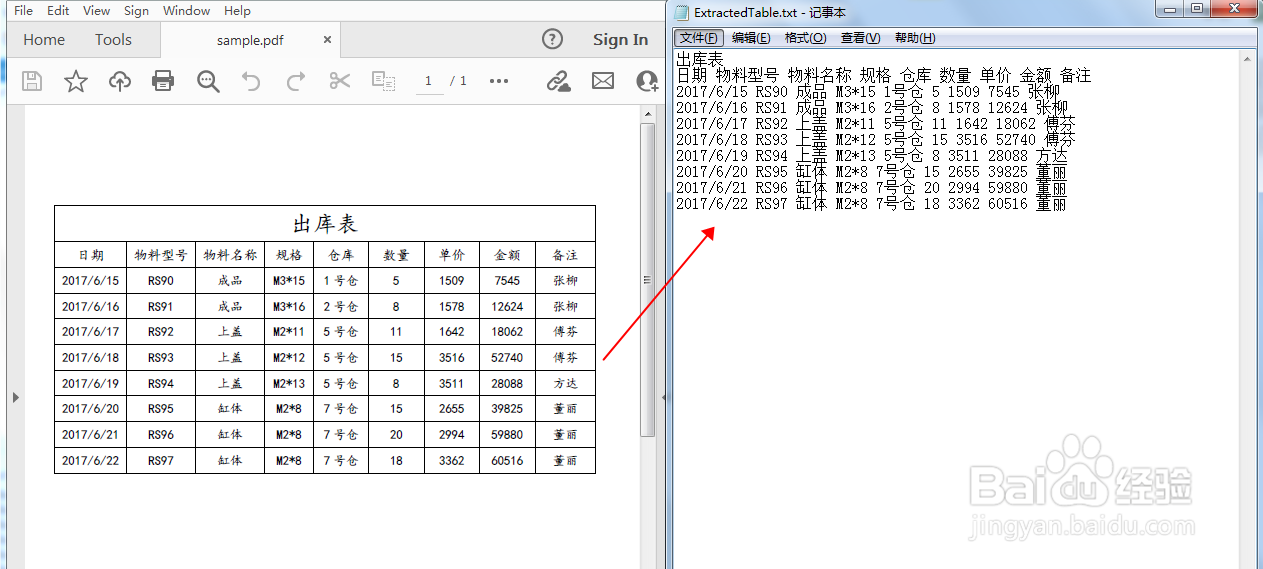
2、完成代码后,执行程序,生成txt文档。表格提取效果如图:
1、Imports Spire.Pdf
Imports Spire.Pdf.Utilities
Imports System.IO
Imports System.Text
Namespace ExtractTable
Class Program
Private Shared Sub Main(args As String())
'加载PDF文档
Dim pdf As New PdfDocument()
pdf.LoadFromFile("sample.pdf")
Dim builder As New StringBuilder()
'抽取表格
Dim extractor As New PdfTableExtractor(pdf)
Dim tableLists As PdfTable() = Nothing
For pageIndex As Integer = 0 To pdf.Pages.Count - 1
tableLists = extractor.ExtractTable(pageIndex)
If tableLists IsNot Nothing AndAlso tableLists.Length > 0 Then
For Each table As PdfTable In tableLists
Dim row As Integer = table.GetRowCount()
Dim column As Integer = table.GetColumnCount()
For i As Integer = 0 To row - 1
For j As Integer = 0 To column - 1
Dim text As String = table.GetText(i, j)
builder.Append(text & Convert.ToString(" "))
Next
builder.Append(vbCr & vbLf)
Next
Next
End If
Next
'保存提取的表格内容到txt文档
File.WriteAllText("ExtractedTable.txt", builder.ToString())
End Sub
End Class
End Namespace