python怎么抓取网站所有链接
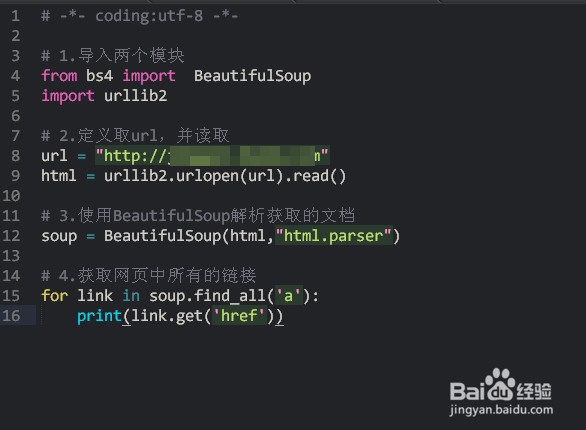
1、新建一个Python文档,并导入两个重要模块,示例:
from bs4 import BeautifulSoup
import urllib2

2、定义想要访问的url,并使用urllib2模块读取内容,示例:
url = "http://www.baidu.com"
html = urllib2.urlopen(url).read()

3、使用BeautifulSoup解析文档,示例:
soup = BeautifulSoup(html,"html.parse")

4、获取网页中所有的<a>标签的href属性值,示例:
for link in soup.find_all('a'):
print(link.get('href'))
5、保存以上内容并在客户端执行,获取网页中的所有连接,示例:
ptyon 保存的文件名

声明:本网站引用、摘录或转载内容仅供网站访问者交流或参考,不代表本站立场,如存在版权或非法内容,请联系站长删除,联系邮箱:site.kefu@qq.com。
阅读量:23
阅读量:171
阅读量:113
阅读量:196
阅读量:44