用tensorflow拟合两组数据的函数关系
1、给出两组随机数:
import tensorflow as tf
import numpy as np
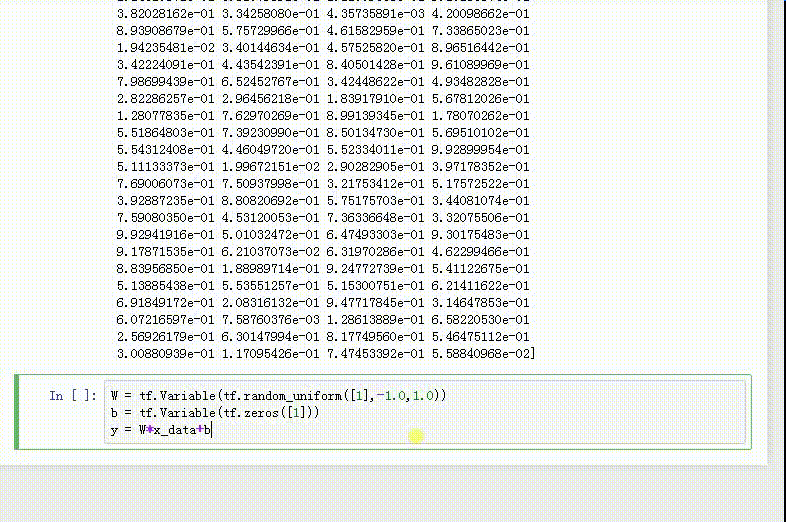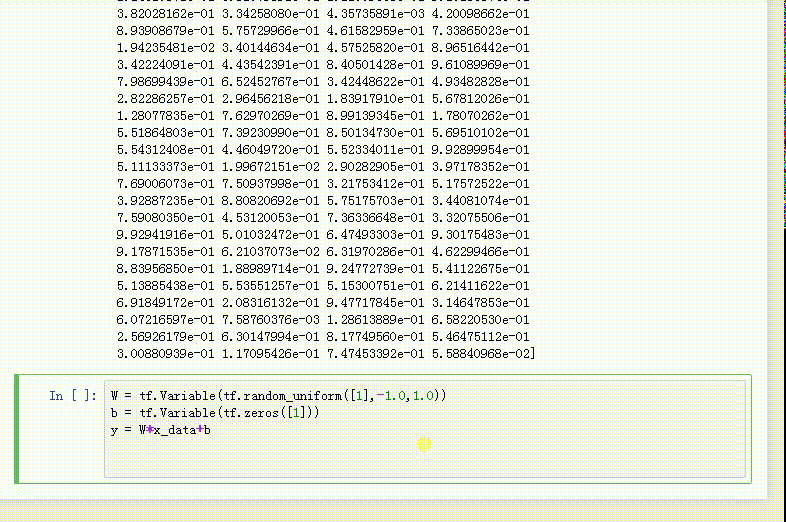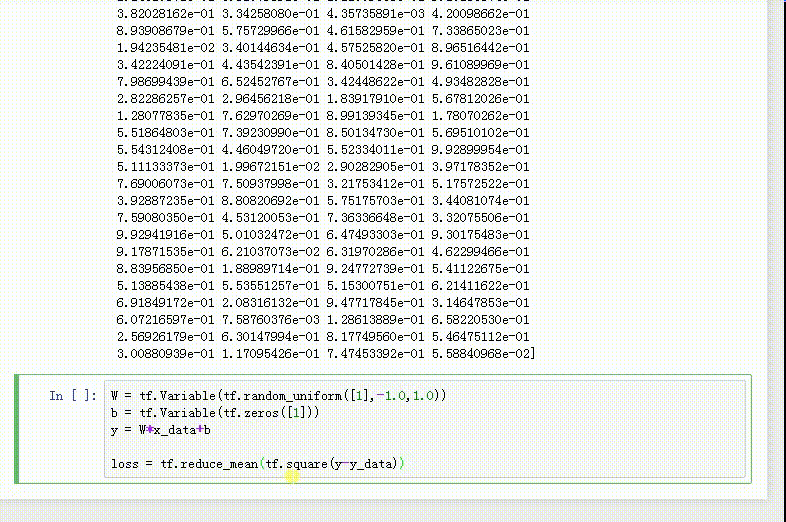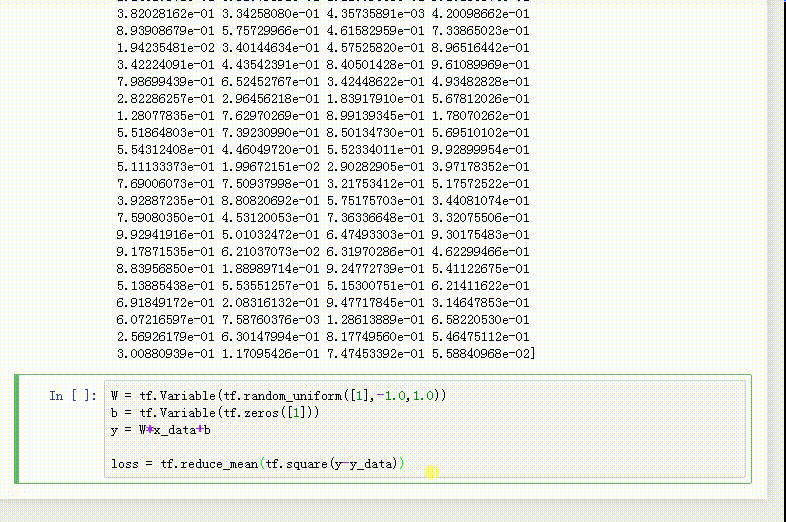
x_data = np.random.rand(300).astype(np.float32)
y_data = np.random.rand(300).astype(np.float32)

2、打印一下x_data,这是由300个随机实数组成的数组。

3、打印一下y_data,也是300个随机实数,与x_data的数字一一对应。

1、本文的目标,是找到一个函数:
y = W*x_data+b
能够尽量拟合给定的数组数据。

2、其中,一次项系数W称为权重,是一个介于-1到1之间的实数:
W = tf.Variable(tf.random_uniform([1],-1.0,1.0))

3、常数项b的初始值是0:
b = tf.Variable(tf.zeros([1]))

4、loss是y与y_data的误差:
loss = tf.reduce_mean(tf.square(y-y_data))
5、用梯度下降法制作一个优化器(optimizer),通过训练,来减少误差:
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)

6、初始化所有的变量:
init = tf.initialize_all_variables()
这样,基本的训练结构就完成了。

1、创建一个对话:
sess = tf.Session()
激活所有的初始化变量:
sess.run(init)

2、开始长达10000次的训练:
for step in range(10001):
sess.run(train)
#每隔100次,就输出一下对应的W和b:
if step%100==0:
print(str(step).rjust(5),sess.run(W),sess.run(b))
训练结束后,关闭对话:
sess.close()

3、运行一下,看看具体的训练过程。

4、在关闭对话之前,还可以插入数据对应的图像,以及训练的函数y对应的图像:
import matplotlib.pyplot as pt
pt.axis('on')
pt.scatter(x_data,y_data,c='g')
pt.scatter(x_data,sess.run(W*x_data+b),
c='r')
pt.show()
图中,绿色点是给出的随机数据的图像,红色线是拟合的函数图像;
由于数据点过于分散,因此,一次函数并不能很好的拟合这组数据;
这里拟合出的y,只是误差尽可能小的一次函数。

